 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-SPARSE: Learning Hierarchical Efficient Transformer Through Regularized Self-Attention
Paper and Code

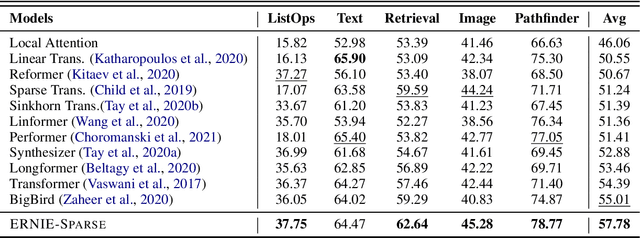

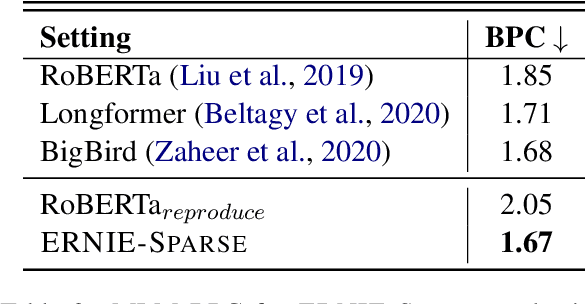
Sparse Transformer has recently attracted a lot of attention since the ability for reducing the quadratic dependency on the sequence length. We argue that two factors, information bottleneck sensitivity and inconsistency between different attention topologies, could affect the performance of the Sparse Transformer. This paper proposes a well-designed model named ERNIE-Sparse. It consists of two distinctive parts: (i) Hierarchical Sparse Transformer (HST) to sequentially unify local and global information. (ii) Self-Attention Regularization (SAR) method, a novel regularization designed to minimize the distance for transformers with different attention topologies. To evaluate the effectiveness of ERNIE-Sparse, we perform extensive evaluations. Firstly, we perform experiments on a multi-modal long sequence modeling task benchmark, Long Range Arena (LRA). Experimental results demonstrate that ERNIE-Sparse significantly outperforms a variety of strong baseline methods including the dense attention and other efficient sparse attention methods and achieves improvements by 2.77% (57.78% vs. 55.01%). Secondly, to further show the effectiveness of our method, we pretrain ERNIE-Sparse and verified it on 3 text classification and 2 QA downstream tasks, achieve improvements on classification benchmark by 0.83% (92.46% vs. 91.63%), on QA benchmark by 3.24% (74.67% vs. 71.43%). Experimental results continue to demonstrate its superior performance.