 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robustness of Vision-Language Models through Orthogonality Learning and Cross-Regularization
Paper and Code
Jul 11, 2024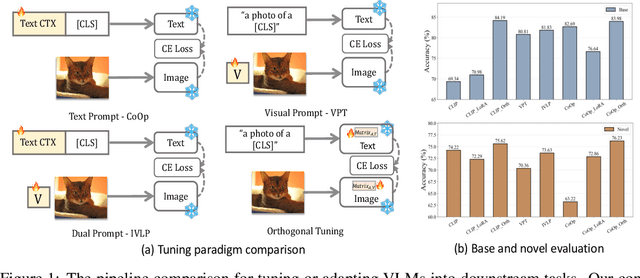
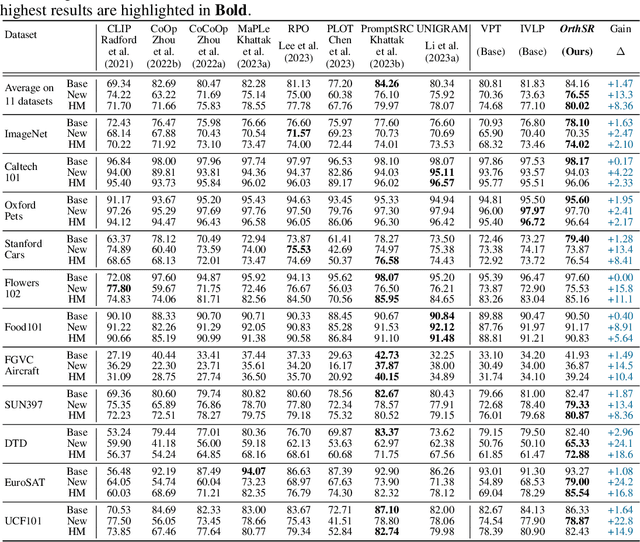
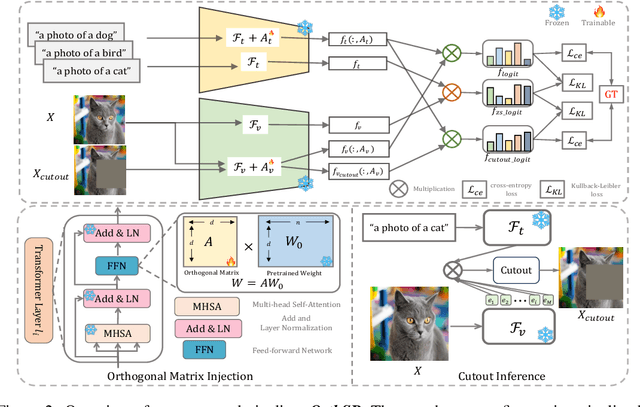
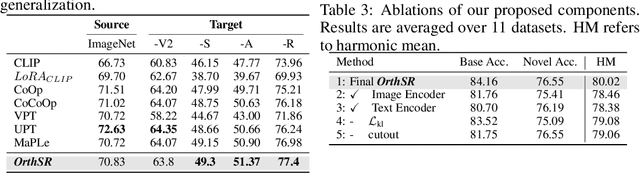
Efficient finetuning of vision-language models (VLMs) like CLIP for specific downstream tasks is gaining significant attention. Previous works primarily focus on prompt learning to adapt the CLIP into a variety of downstream tasks, however, suffering from task overfitting when finetuned on a small data set. In this paper, we introduce an orthogonal finetuning method for efficiently updating pretrained weights which enhances robustness and generalization, while a cross-regularization strategy is further exploited to maintain the stability in terms of zero-shot generalization of VLMs, dubbed \textbf{\textit{OrthCR}}. Specifically, trainable orthogonal matrices are injected seamlessly into the transformer architecture and enforced with orthogonality constraint using Cayley parameterization, benefiting from the norm-preserving property and thus leading to stable and faster convergence. To alleviate deviation from orthogonal constraint during training, a cross-regularization strategy is further employed with initial pretrained weights within a bypass manner. In addition, to enrich the sample diversity for downstream tasks, we first explore Cutout data augmentation to boost the efficient finetuning and comprehend how our approach improves the specific downstream performance and maintains the generalizability in the perspective of Orthogonality Learning. Beyond existing prompt learning techniques, we conduct extensive experiments to demonstrate that our method explicitly steers pretrained weight space to represent the task-specific knowledge and presents competitive generalizability under \textit{base-to-base/base-to-new}, \textit{cross-dataset transfer} and \textit{domain generalization} evaluations.