 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Quadratic Video Interpolation
Paper and Code

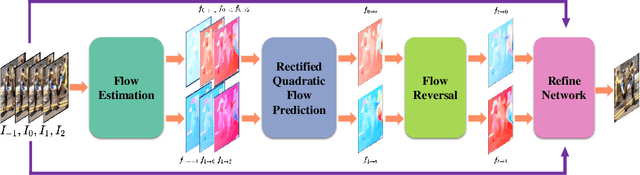
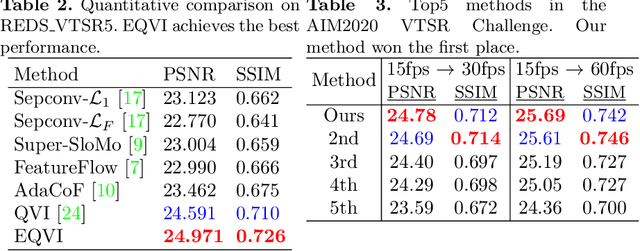
With the prosperity of digital video industry, video frame interpolation has arisen continuous attention in computer vision community and become a new upsurge in industry. Many learning-based methods have been proposed and achieved progressive results. Among them, a recent algorithm named quadratic video interpolation (QVI) achieves appealing performance. It exploits higher-order motion information (e.g. acceleration) and successfully models the estimation of interpolated flow. However, its produced intermediate frames still contain some unsatisfactory ghosting, artifacts and inaccurate motion, especially when large and complex motion occurs. In this work, we further improve the performance of QVI from three facets and propose an enhanced quadratic video interpolation (EQVI) model. In particular, we adopt a rectified quadratic flow prediction (RQFP) formulation with least squares method to estimate the motion more accurately. Complementary with image pixel-level blending, we introduce a residual contextual synthesis network (RCSN) to employ contextual information in high-dimensional feature space, which could help the model handle more complicated scenes and motion patterns. Moreover, to further boost the performance, we devise a novel multi-scale fusion network (MS-Fusion) which can be regarded as a learnable augmentation process. The proposed EQVI model won the first place in the AIM2020 Video Temporal Super-Resolution Challenge.