 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Automatic Speech Recognition Integrated With CTC-Based Voice Activity Detection
Paper and Code
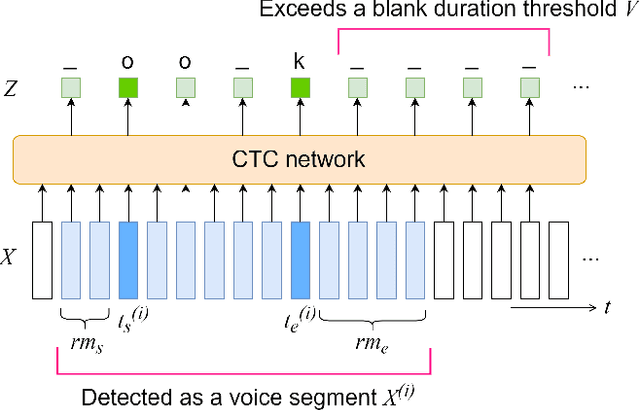
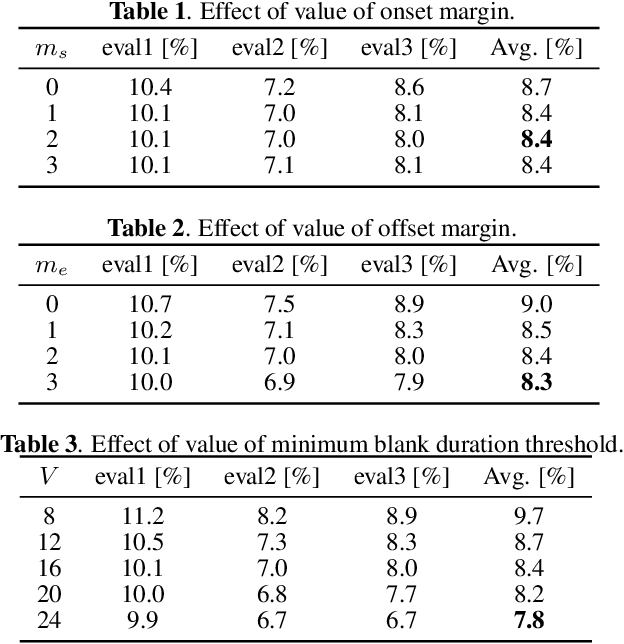
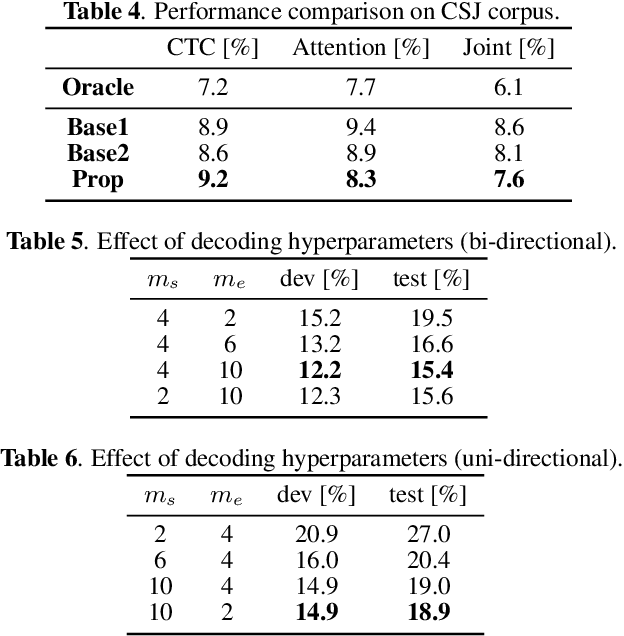

This paper integrates a voice activity detection (VAD) function with end-to-end automatic speech recognition toward an online speech interface and transcribing very long audio recordings. We focus on connectionist temporal classification (CTC) and its extension of CTC/attention architectures. As opposed to an attention-based architecture, input-synchronous label prediction can be performed based on a greedy search with the CTC (pre-)softmax output. This prediction includes consecutive long blank labels, which can be regarded as a non-speech region. We use the labels as a cue for detecting speech segments with simple thresholding. The threshold value is directly related to the length of a non-speech region, which is more intuitive and easier to control than conventional VAD hyperparameters. Experimental results on unsegmented data show that the proposed method outperformed the baseline methods using the conventional energy-based and neural-network-based VAD methods and achieved an RTF less than 0.2. The proposed method is publicly available.