 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Massive Deep Neural Networks with the GraphBLAS
Paper and Code
Aug 09, 2017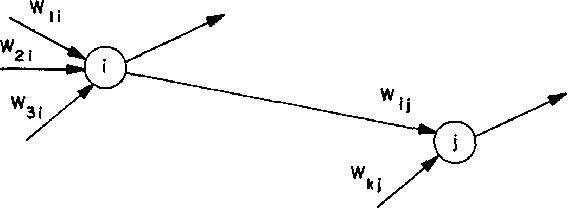
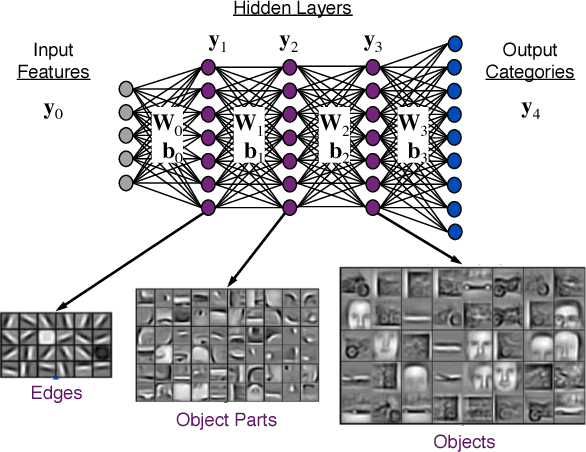
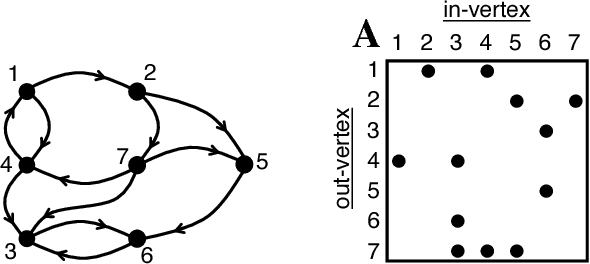

Deep Neural Networks (DNNs) have emerged as a core tool for machine learning. The computations performed during DNN training and inference are dominated by operations on the weight matrices describing the DNN. As DNNs incorporate more stages and more nodes per stage, these weight matrices may be required to be sparse because of memory limitations. The GraphBLAS.org math library standard was developed to provide high performance manipulation of sparse weight matrices and input/output vectors. For sufficiently sparse matrices, a sparse matrix library requires significantly less memory than the corresponding dense matrix implementation. This paper provides a brief description of the mathematics underlying the GraphBLAS. In addition, the equations of a typical DNN are rewritten in a form designed to use the GraphBLAS. An implementation of the DNN is given using a preliminary GraphBLAS C library. The performance of the GraphBLAS implementation is measured relative to a standard dense linear algebra library implementation. For various sizes of DNN weight matrices, it is shown that the GraphBLAS sparse implementation outperforms a BLAS dense implementation as the weight matrix becomes sparser.