 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Paper and Code
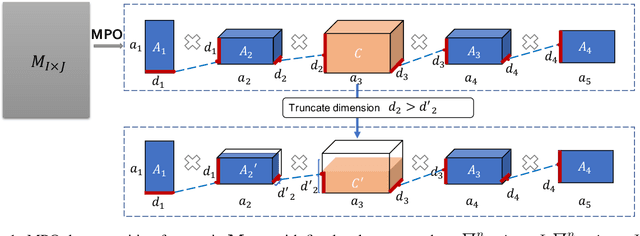
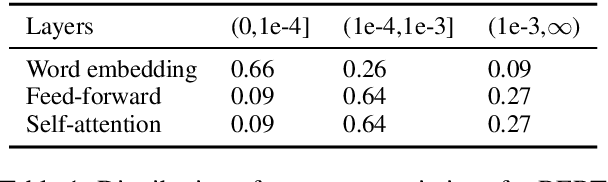
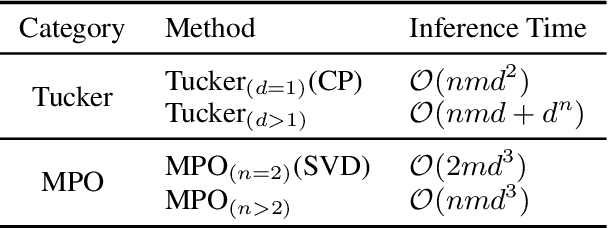
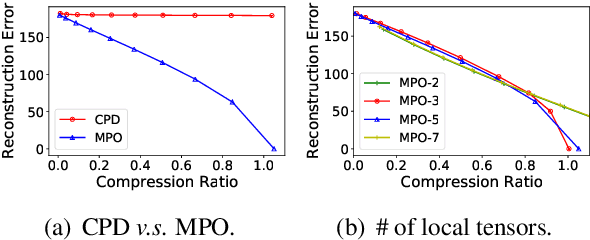
This paper presents a novel pre-trained language models (PLM) compression approach based on the matrix product operator (short as MPO) from quantum many-body physics. It can decompose an original matrix into central tensors (containing the core information) and auxiliary tensors (with only a small proportion of parameters). With the decomposed MPO structure, we propose a novel fine-tuning strategy by only updating the parameters from the auxiliary tensors, and design an optimization algorithm for MPO-based approximation over stacked network architectures. Our approach can be applied to the original or the compressed PLMs in a general way, which derives a lighter network and significantly reduces the parameters to be fine-tuned. Extensive experiments have demonstrated the effectiveness of the proposed approach in model compression, especially the reduction in finetuning parameters (91% reduction on average).