 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Principle in Depth for the Loss Landscape Analysis of Deep Neural Networks
Paper and Code
May 26, 2022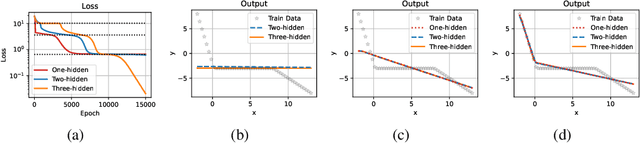
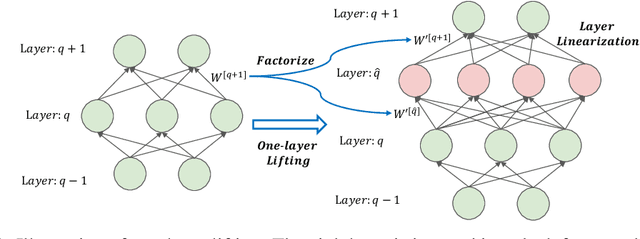


Unraveling the general structure underlying the loss landscapes of deep neural networks (DNNs) is important for the theoretical study of deep learning. Inspired by the embedding principle of DNN loss landscape, we prove in this work an embedding principle in depth that loss landscape of an NN "contains" all critical points of the loss landscapes for shallower NNs. Specifically, we propose a critical lifting operator that any critical point of a shallower network can be lifted to a critical manifold of the target network while preserving the outputs. Through lifting, local minimum of an NN can become a strict saddle point of a deeper NN, which can be easily escaped by first-order methods. The embedding principle in depth reveals a large family of critical points in which layer linearization happens, i.e., computation of certain layers is effectively linear for the training inputs. We empirically demonstrate that, through suppressing layer linearization, batch normalization helps avoid the lifted critical manifolds, resulting in a faster decay of loss. We also demonstrate that increasing training data reduces the lifted critical manifold thus could accelerate the training. Overall, the embedding principle in depth well complements the embedding principle (in width), resulting in a complete characterization of the hierarchical structure of critical points/manifolds of a DNN loss landscape.