 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning
Paper and Code
Dec 11, 2021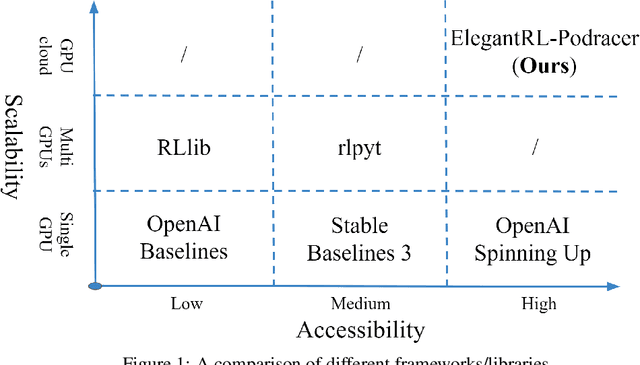
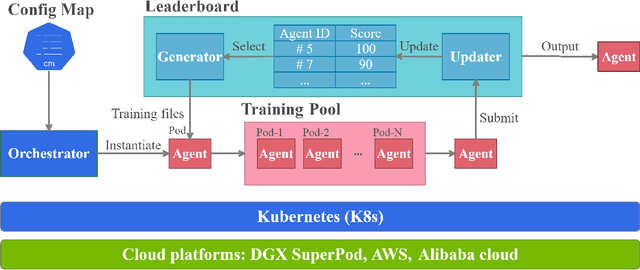

Deep reinforcement learning (DRL) has revolutionized learning and actuation in applications such as game playing and robotic control. The cost of data collection, i.e., generating transitions from agent-environment interactions, remains a major challenge for wider DRL adoption in complex real-world problems. Following a cloud-native paradigm to train DRL agents on a GPU cloud platform is a promising solution. In this paper, we present a scalable and elastic library ElegantRL-podracer for cloud-native deep reinforcement learning, which efficiently supports millions of GPU cores to carry out massively parallel training at multiple levels. At a high-level, ElegantRL-podracer employs a tournament-based ensemble scheme to orchestrate the training process on hundreds or even thousands of GPUs, scheduling the interactions between a leaderboard and a training pool with hundreds of pods. At a low-level, each pod simulates agent-environment interactions in parallel by fully utilizing nearly 7,000 GPU CUDA cores in a single GPU. Our ElegantRL-podracer library features high scalability, elasticity and accessibility by following the development principles of containerization, microservices and MLOps. Using an NVIDIA DGX SuperPOD cloud, we conduct extensive experiments on various tasks in locomotion and stock trading and show that ElegantRL-podracer substantially outperforms RLlib. Our codes are available on GitHub.