 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientTrain: Exploring Generalized Curriculum Learning for Training Visual Backbones
Paper and Code
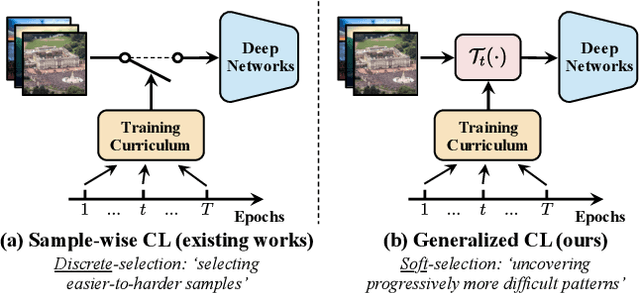
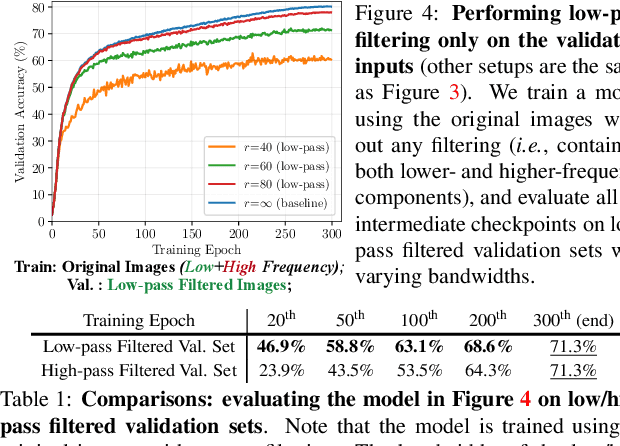
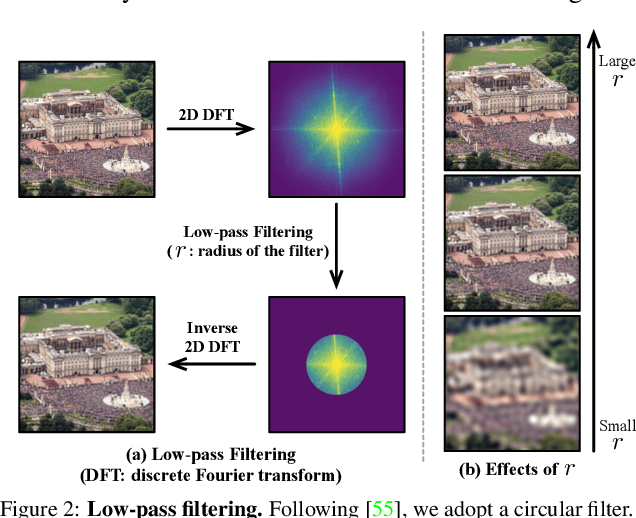
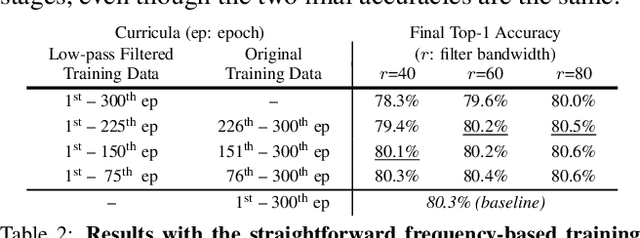
The superior performance of modern deep networks usually comes at the price of a costly training procedure. In this paper, we present a novel curriculum learning approach for the efficient training of visual backbones (e.g., vision Transformers). The proposed method is inspired by the phenomenon that deep networks mainly learn to recognize some 'easier-to-learn' discriminative patterns within each example at earlier stages of training, e.g., the lower-frequency components of images and the original information before data augmentation. Driven by this observation, we propose a curriculum where the model always leverages all the training data at each epoch, while the curriculum starts with only exposing the 'easier-to-learn' patterns of each example, and introduces gradually more difficult patterns. To implement this idea, we 1) introduce a cropping operation in the Fourier spectrum of the inputs, which enables the model to learn from only the lower-frequency components efficiently, and 2) demonstrate that exposing the features of original images amounts to adopting weaker data augmentation. Our resulting algorithm, EfficientTrain, is simple, general, yet surprisingly effective. For example, it reduces the training time of a wide variety of popular models (e.g., ConvNeXts, DeiT, PVT, and Swin/CSWin Transformers) by more than ${1.5\times}$ on ImageNet-1K/22K without sacrificing the accuracy. It is effective for self-supervised learning (i.e., MAE) as well. Code is available at https://github.com/LeapLabTHU/EfficientTrain.