 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Protocols for Distributed Classification and Optimization
Paper and Code
Apr 16, 2012
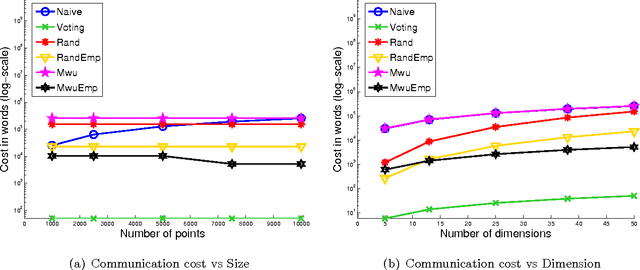
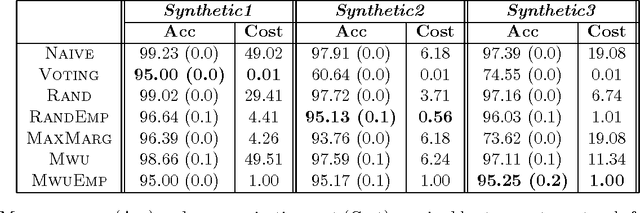
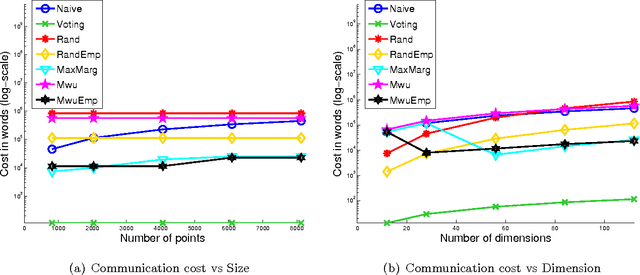
In distributed learning, the goal is to perform a learning task over data distributed across multiple nodes with minimal (expensive) communication. Prior work (Daume III et al., 2012) proposes a general model that bounds the communication required for learning classifiers while allowing for $\eps$ training error on linearly separable data adversarially distributed across nodes. In this work, we develop key improvements and extensions to this basic model. Our first result is a two-party multiplicative-weight-update based protocol that uses $O(d^2 \log{1/\eps})$ words of communication to classify distributed data in arbitrary dimension $d$, $\eps$-optimally. This readily extends to classification over $k$ nodes with $O(kd^2 \log{1/\eps})$ words of communication. Our proposed protocol is simple to implement and is considerably more efficient than baselines compared, as demonstrated by our empirical results. In addition, we illustrate general algorithm design paradigms for doing efficient learning over distributed data. We show how to solve fixed-dimensional and high dimensional linear programming efficiently in a distributed setting where constraints may be distributed across nodes. Since many learning problems can be viewed as convex optimization problems where constraints are generated by individual points, this models many typical distributed learning scenarios. Our techniques make use of a novel connection from multipass streaming, as well as adapting the multiplicative-weight-update framework more generally to a distributed setting. As a consequence, our methods extend to the wide range of problems solvable using these techniques.