 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Radiance Fields with Learned Depth-Guided Sampling
Paper and Code
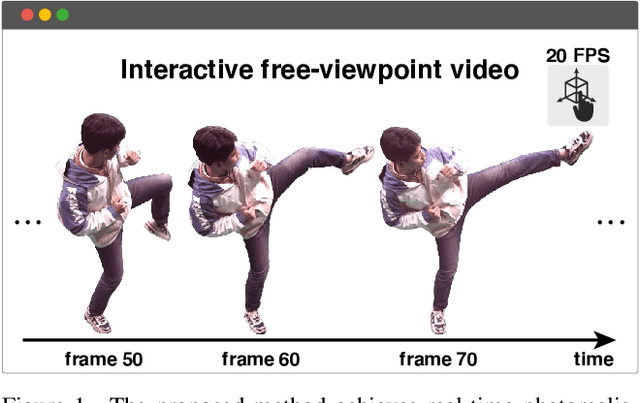
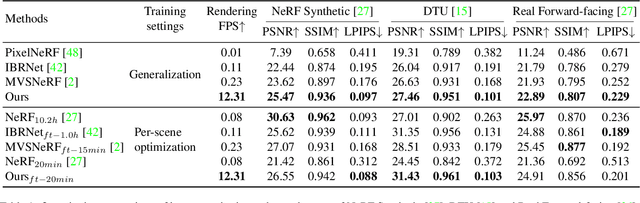
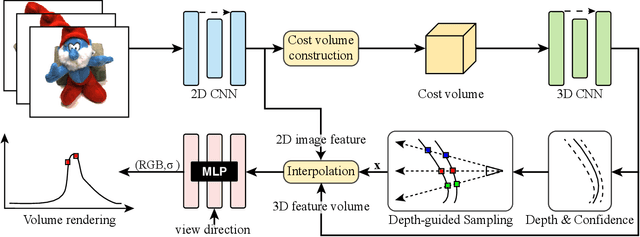
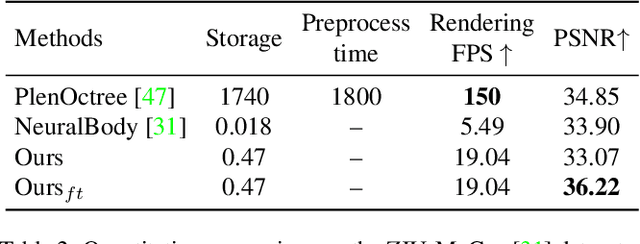
This paper aims to reduce the rendering time of generalizable radiance fields. Some recent works equip neural radiance fields with image encoders and are able to generalize across scenes, which avoids the per-scene optimization. However, their rendering process is generally very slow. A major factor is that they sample lots of points in empty space when inferring radiance fields. In this paper, we present a hybrid scene representation which combines the best of implicit radiance fields and explicit depth maps for efficient rendering. Specifically, we first build the cascade cost volume to efficiently predict the coarse geometry of the scene. The coarse geometry allows us to sample few points near the scene surface and significantly improves the rendering speed. This process is fully differentiable, enabling us to jointly learn the depth prediction and radiance field networks from only RGB images. Experiments show that the proposed approach exhibits state-of-the-art performance on the DTU, Real Forward-facing and NeRF Synthetic datasets, while being at least 50 times faster than previous generalizable radiance field methods. We also demonstrate the capability of our method to synthesize free-viewpoint videos of dynamic human performers in real-time. The code will be available at https://zju3dv.github.io/enerf/.