Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Identification of Approximate Best Configuration of Training in Large Datasets
Paper and Code
Nov 08, 2018
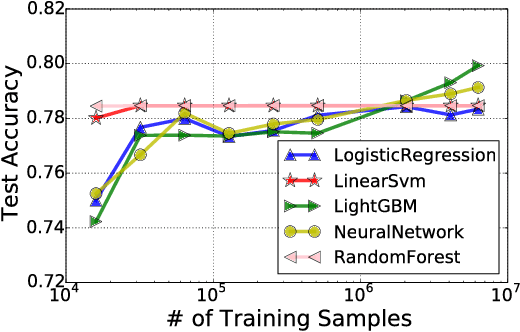

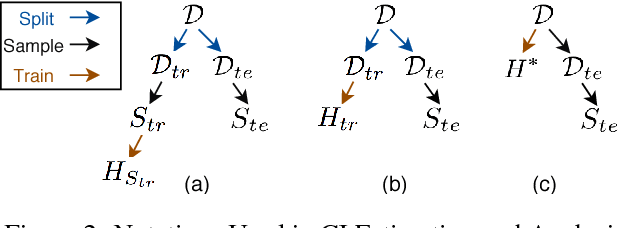
A configuration of training refers to the combinations of feature engineering, learner, and its associated hyperparameters. Given a set of configurations and a large dataset randomly split into training and testing set, we study how to efficiently identify the best configuration with approximately the highest testing accuracy when trained from the training set. To guarantee small accuracy loss, we develop a solution using confidence interval (CI)-based progressive sampling and pruning strategy. Compared to using full data to find the exact best configuration, our solution achieves more than two orders of magnitude speedup, while the returned top configuration has identical or close test accuracy.
* Full version of an AAAI 2019 conference paper
View paper on