 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient GPU implementation of randomized SVD and its applications
Paper and Code
Oct 05, 2021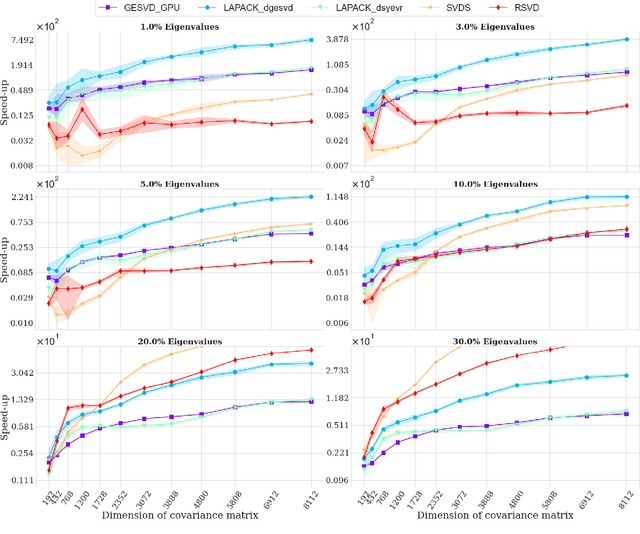



Matrix decompositions are ubiquitous in machine learning, including applications in dimensionality reduction, data compression and deep learning algorithms. Typical solutions for matrix decompositions have polynomial complexity which significantly increases their computational cost and time. In this work, we leverage efficient processing operations that can be run in parallel on modern Graphical Processing Units (GPUs), predominant computing architecture used e.g. in deep learning, to reduce the computational burden of computing matrix decompositions. More specifically, we reformulate the randomized decomposition problem to incorporate fast matrix multiplication operations (BLAS-3) as building blocks. We show that this formulation, combined with fast random number generators, allows to fully exploit the potential of parallel processing implemented in GPUs. Our extensive evaluation confirms the superiority of this approach over the competing methods and we release the results of this research as a part of the official CUDA implementation (https://docs.nvidia.com/cuda/cusolver/index.html).