 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Gaussian Process Bandits by Believing only Informative Actions
Paper and Code
Mar 23, 2020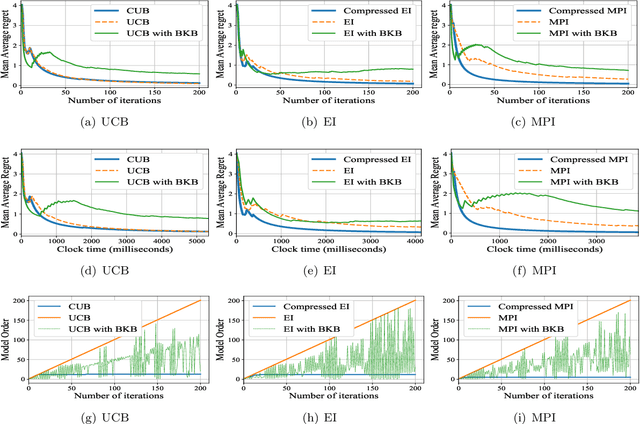
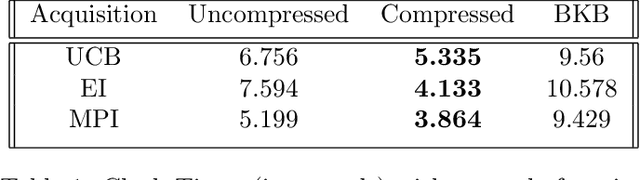

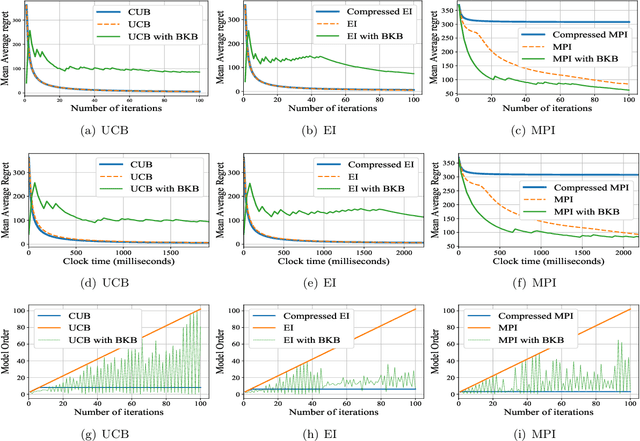
Bayesian optimization is a framework for global search via maximum a posteriori updates rather than simulated annealing, and has gained prominence for decision-making under uncertainty. In this work, we cast Bayesian optimization as a multi-armed bandit problem, where the payoff function is sampled from a Gaussian process (GP). Further, we focus on action selections via upper confidence bound (UCB) or expected improvement (EI) due to their prevalent use in practice. Prior works using GPs for bandits cannot allow the iteration horizon $T$ to be large, as the complexity of computing the posterior parameters scales cubically with the number of past observations. To circumvent this computational burden, we propose a simple statistical test: only incorporate an action into the GP posterior when its conditional entropy exceeds an $\epsilon$ threshold. Doing so permits us to derive sublinear regret bounds of GP bandit algorithms up to factors depending on the compression parameter $\epsilon$ for both discrete and continuous action sets. Moreover, the complexity of the GP posterior remains provably finite. Experimentally, we observe state of the art accuracy and complexity tradeoffs for GP bandit algorithms applied to global optimization, suggesting the merits of compressed GPs in bandit settings.