 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Abnormality Mining from Radiology Reports with Customized False Positive Reduction
Paper and Code
Oct 01, 2018

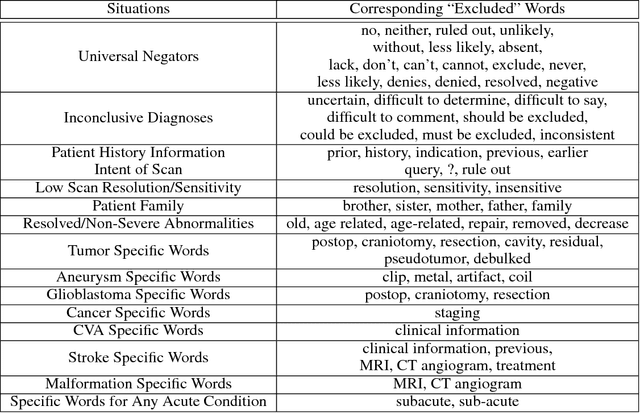
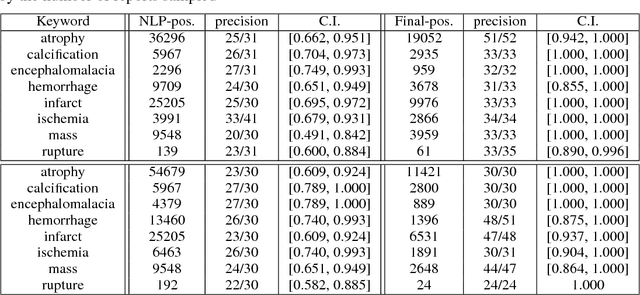
Obtaining datasets labeled to facilitate model development is a challenge for most machine learning tasks. The difficulty is heightened for medical imaging, where data itself is limited in accessibility and labeling requires costly time and effort by trained medical specialists. Medical imaging studies, however, are often accompanied by a medical report produced by a radiologist, identifying important features on the corresponding scan for other physicians not specifically trained in radiology. We propose a methodology for approximating image-level labels for radiology studies from associated reports using a general purpose language processing tool for medical concept extraction and sentiment analysis, and simple manually crafted heuristics for false positive reduction. Using this approach, we label more than 175,000 Head CT studies for the presence of 33 features indicative of 11 clinically relevant conditions. For 27 of the 30 keywords that yielded positive results (3 had no occurrences), the lower bound of the confidence intervals created to estimate the percentage of accurately labeled reports was above 85%, with the average being above 95%. Though noisier then manual labeling, these results suggest this method to be a viable means of labeling medical images at scale.