 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Language Binding in Relational Visual Reasoning
Paper and Code
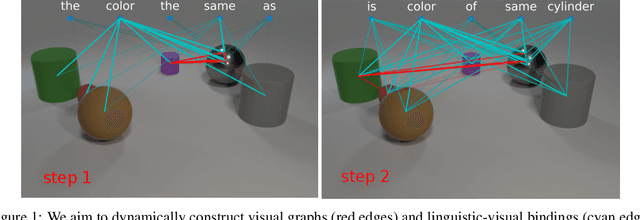
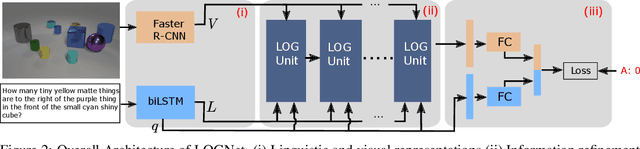
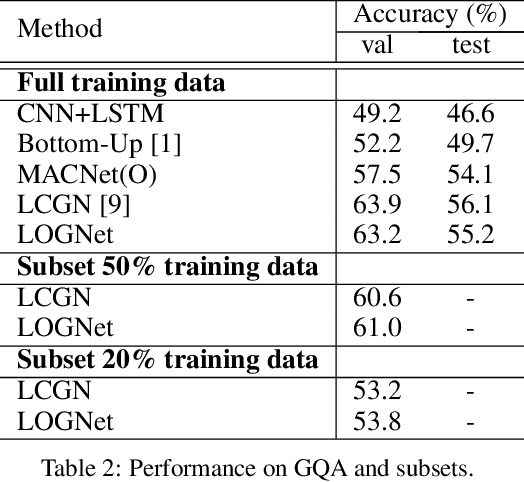
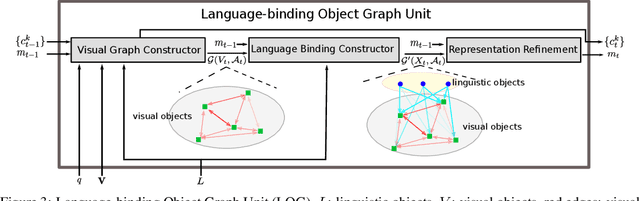
We present Language-binding Object Graph Network, the first neural reasoning method with dynamic relational structures across both visual and textual domains with applications in visual question answering. Relaxing the common assumption made by current models that the object predicates pre-exist and stay static, passive to the reasoning process, we propose that these dynamic predicates expand across the domain borders to include pair-wise visual-linguistic object binding. In our method, these contextualized object links are actively found within each recurrent reasoning step without relying on external predicative priors. These dynamic structures reflect the conditional dual-domain object dependency given the evolving context of the reasoning through co-attention. Such discovered dynamic graphs facilitate multi-step knowledge combination and refinements that iteratively deduce the compact representation of the final answer. The effectiveness of this model is demonstrated on image question answering demonstrating favorable performance on major VQA datasets. Our method outperforms other methods in sophisticated question-answering tasks wherein multiple object relations are involved. The graph structure effectively assists the progress of training, and therefore the network learns efficiently compared to other reasoning models.