 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph Message Passing Networks for Visual Recognition
Paper and Code


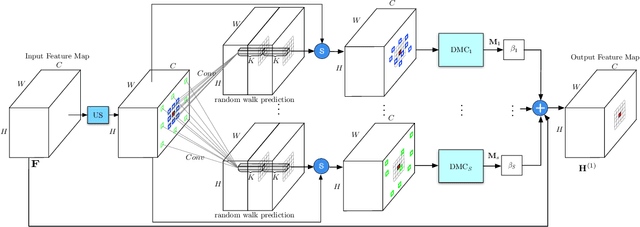
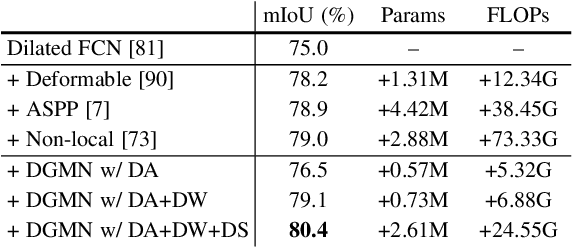
Modelling long-range dependencies is critical for scene understanding tasks in computer vision. Although convolution neural networks (CNNs) have excelled in many vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph, such as the self-attention operation in Transformers, is beneficial for such modelling, however, its computational overhead is prohibitive. In this paper, we propose a dynamic graph message passing network, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. This formulation allows us to design a self-attention module, and more importantly a new Transformer-based backbone network, that we use for both image classification pretraining, and for addressing various downstream tasks (object detection, instance and semantic segmentation). Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on four different tasks. Our approach also outperforms fully-connected graphs while using substantially fewer floating-point operations and parameters. Code and models will be made publicly available at https://github.com/fudan-zvg/DGMN2