 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVD: A Diagnostic Dataset for Multi-step Reasoning in Video Grounded Dialogue
Paper and Code
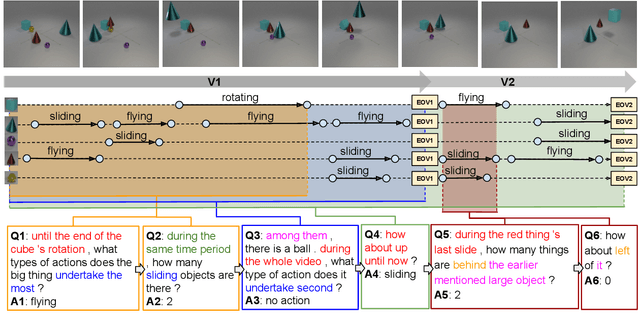
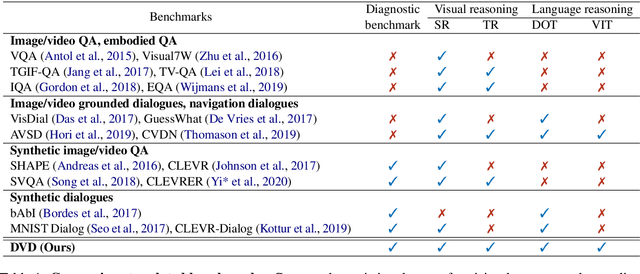
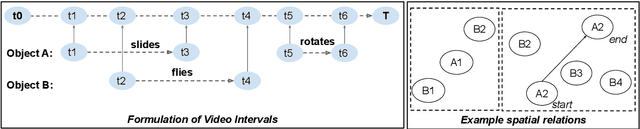
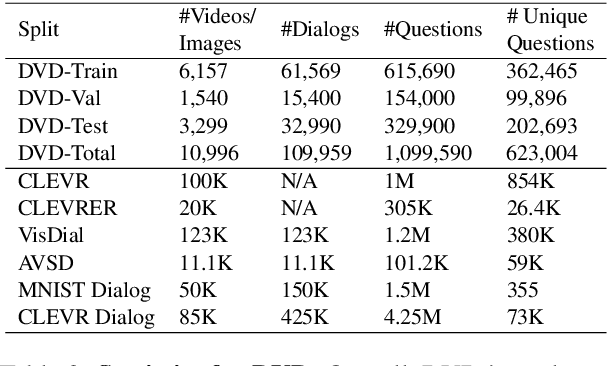
A video-grounded dialogue system is required to understand both dialogue, which contains semantic dependencies from turn to turn, and video, which contains visual cues of spatial and temporal scene variations. Building such dialogue systems is a challenging problem involving complex multimodal and temporal inputs, and studying them independently is hard with existing datasets. Existing benchmarks do not have enough annotations to help analyze dialogue systems and understand their linguistic and visual reasoning capability and limitations in isolation. These benchmarks are also not explicitly designed to minimize biases that models can exploit without actual reasoning. To address these limitations, in this paper, we present a diagnostic dataset that can test a range of reasoning abilities on videos and dialogues. The dataset is designed to contain minimal biases and has detailed annotations for the different types of reasoning each question requires, including cross-turn video interval tracking and dialogue object tracking. We use our dataset to analyze several dialogue system approaches, providing interesting insights into their abilities and limitations. In total, the dataset contains $10$ instances of $10$-round dialogues for each of $\sim11k$ synthetic videos, resulting in more than $100k$ dialogues and $1M$ question-answer pairs. Our code and dataset will be made public.