 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSE-GAN: Dynamic Semantic Evolution Generative Adversarial Network for Text-to-Image Generation
Paper and Code
Sep 03, 2022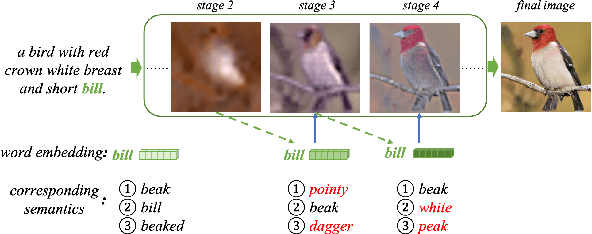



Text-to-image generation aims at generating realistic images which are semantically consistent with the given text. Previous works mainly adopt the multi-stage architecture by stacking generator-discriminator pairs to engage multiple adversarial training, where the text semantics used to provide generation guidance remain static across all stages. This work argues that text features at each stage should be adaptively re-composed conditioned on the status of the historical stage (i.e., historical stage's text and image features) to provide diversified and accurate semantic guidance during the coarse-to-fine generation process. We thereby propose a novel Dynamical Semantic Evolution GAN (DSE-GAN) to re-compose each stage's text features under a novel single adversarial multi-stage architecture. Specifically, we design (1) Dynamic Semantic Evolution (DSE) module, which first aggregates historical image features to summarize the generative feedback, and then dynamically selects words required to be re-composed at each stage as well as re-composed them by dynamically enhancing or suppressing different granularity subspace's semantics. (2) Single Adversarial Multi-stage Architecture (SAMA), which extends the previous structure by eliminating complicated multiple adversarial training requirements and therefore allows more stages of text-image interactions, and finally facilitates the DSE module. We conduct comprehensive experiments and show that DSE-GAN achieves 7.48\% and 37.8\% relative FID improvement on two widely used benchmarks, i.e., CUB-200 and MSCOCO, respectively.