 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-Linear Thompson Sampling for Context-Attentive Bandits
Paper and Code
Oct 15, 2020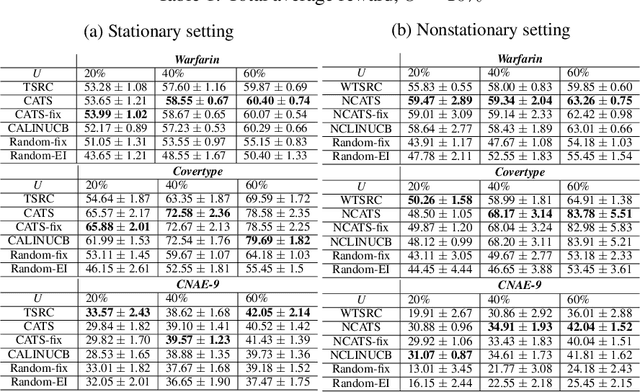
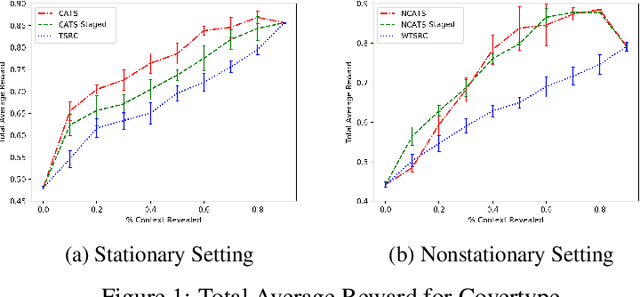
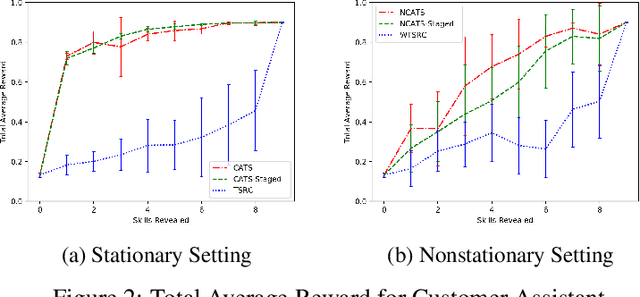
In this paper, we analyze and extend an online learning framework known as Context-Attentive Bandit, motivated by various practical applications, from medical diagnosis to dialog systems, where due to observation costs only a small subset of a potentially large number of context variables can be observed at each iteration;however, the agent has a freedom to choose which variables to observe. We derive a novel algorithm, called Context-Attentive Thompson Sampling (CATS), which builds upon the Linear Thompson Sampling approach, adapting it to Context-Attentive Bandit setting. We provide a theoretical regret analysis and an extensive empirical evaluation demonstrating advantages of the proposed approach over several baseline methods on a variety of real-life datasets