 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Pre-trained Language Model Actually Infer Unseen Links in Knowledge Graph Completion?
Paper and Code


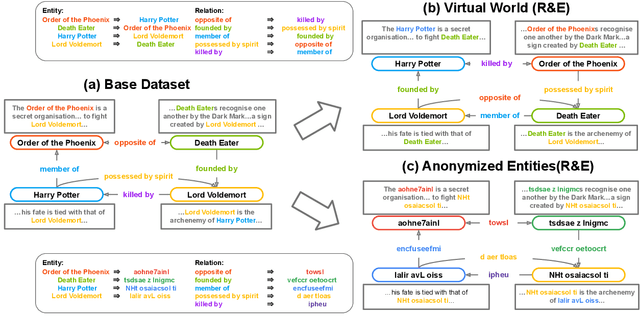

Knowledge graphs (KGs) consist of links that describe relationships between entities. Due to the difficulty of manually enumerating all relationships between entities, automatically completing them is essential for KGs. Knowledge Graph Completion (KGC) is a task that infers unseen relationships between entities in a KG. Traditional embedding-based KGC methods, such as RESCAL, TransE, DistMult, ComplEx, RotatE, HAKE, HousE, etc., infer missing links using only the knowledge from training data. In contrast, the recent Pre-trained Language Model (PLM)-based KGC utilizes knowledge obtained during pre-training. Therefore, PLM-based KGC can estimate missing links between entities by reusing memorized knowledge from pre-training without inference. This approach is problematic because building KGC models aims to infer unseen links between entities. However, conventional evaluations in KGC do not consider inference and memorization abilities separately. Thus, a PLM-based KGC method, which achieves high performance in current KGC evaluations, may be ineffective in practical applications. To address this issue, we analyze whether PLM-based KGC methods make inferences or merely access memorized knowledge. For this purpose, we propose a method for constructing synthetic datasets specified in this analysis and conclude that PLMs acquire the inference abilities required for KGC through pre-training, even though the performance improvements mostly come from textual information of entities and relations.