 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Neural Autoregressive Distribution Estimation
Paper and Code
Mar 18, 2016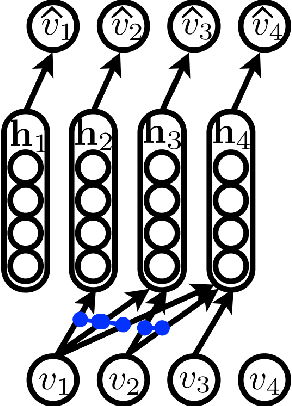


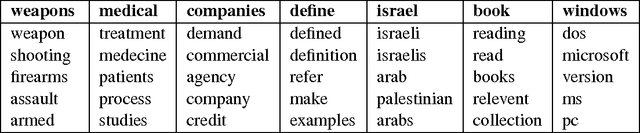
We present an approach based on feed-forward neural networks for learning the distribution of textual documents. This approach is inspired by the Neural Autoregressive Distribution Estimator(NADE) model, which has been shown to be a good estimator of the distribution of discrete-valued igh-dimensional vectors. In this paper, we present how NADE can successfully be adapted to the case of textual data, retaining from NADE the property that sampling or computing the probability of observations can be done exactly and efficiently. The approach can also be used to learn deep representations of documents that are competitive to those learned by the alternative topic modeling approaches. Finally, we describe how the approach can be combined with a regular neural network N-gram model and substantially improve its performance, by making its learned representation sensitive to the larger, document-specific context.