 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN adaptation by automatic quality estimation of ASR hypotheses
Paper and Code
Feb 06, 2017
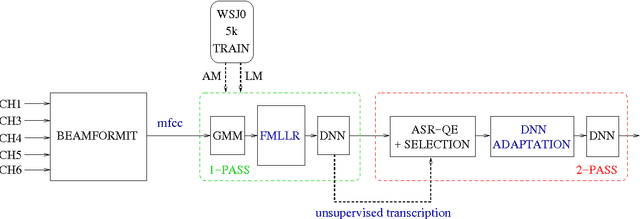


In this paper we propose to exploit the automatic Quality Estimation (QE) of ASR hypotheses to perform the unsupervised adaptation of a deep neural network modeling acoustic probabilities. Our hypothesis is that significant improvements can be achieved by: i)automatically transcribing the evaluation data we are currently trying to recognise, and ii) selecting from it a subset of "good quality" instances based on the word error rate (WER) scores predicted by a QE component. To validate this hypothesis, we run several experiments on the evaluation data sets released for the CHiME-3 challenge. First, we operate in oracle conditions in which manual transcriptions of the evaluation data are available, thus allowing us to compute the "true" sentence WER. In this scenario, we perform the adaptation with variable amounts of data, which are characterised by different levels of quality. Then, we move to realistic conditions in which the manual transcriptions of the evaluation data are not available. In this case, the adaptation is performed on data selected according to the WER scores "predicted" by a QE component. Our results indicate that: i) QE predictions allow us to closely approximate the adaptation results obtained in oracle conditions, and ii) the overall ASR performance based on the proposed QE-driven adaptation method is significantly better than the strong, most recent, CHiME-3 baseline.