 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDKDM: Data-Free Knowledge Distillation for Diffusion Models with Any Architecture
Paper and Code

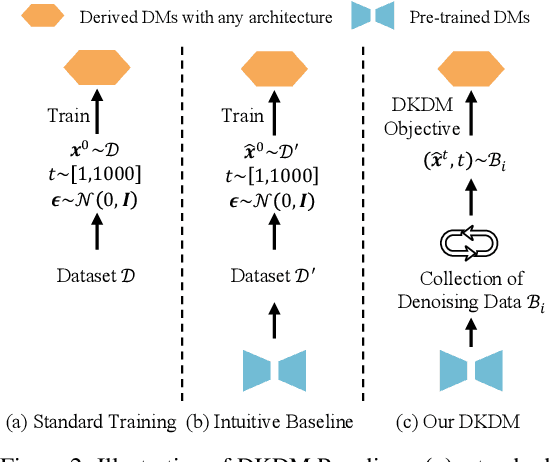

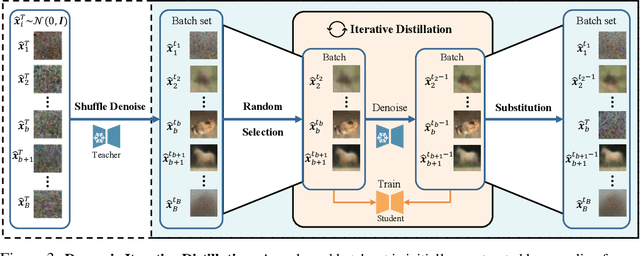
Diffusion models (DMs) have demonstrated exceptional generative capabilities across various areas, while they are hindered by slow inference speeds and high computational demands during deployment. The most common way to accelerate DMs involves reducing the number of denoising steps during generation, achieved through faster sampling solvers or knowledge distillation (KD). In contrast to prior approaches, we propose a novel method that transfers the capability of large pretrained DMs to faster architectures. Specifically, we employ KD in a distinct manner to compress DMs by distilling their generative ability into more rapid variants. Furthermore, considering that the source data is either unaccessible or too enormous to store for current generative models, we introduce a new paradigm for their distillation without source data, termed Data-Free Knowledge Distillation for Diffusion Models (DKDM). Generally, our established DKDM framework comprises two main components: 1) a DKDM objective that uses synthetic denoising data produced by pretrained DMs to optimize faster DMs without source data, and 2) a dynamic iterative distillation method that flexibly organizes the synthesis of denoising data, preventing it from slowing down the optimization process as the generation is slow. To our knowledge, this is the first attempt at using KD to distill DMs into any architecture in a data-free manner. Importantly, our DKDM is orthogonal to most existing acceleration methods, such as denoising step reduction, quantization and pruning. Experiments show that our DKDM is capable of deriving 2x faster DMs with performance remaining on par with the baseline. Notably, our DKDM enables pretrained DMs to function as "datasets" for training new DMs.