 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Context Aware Loss for Person Re-identification
Paper and Code
Nov 17, 2019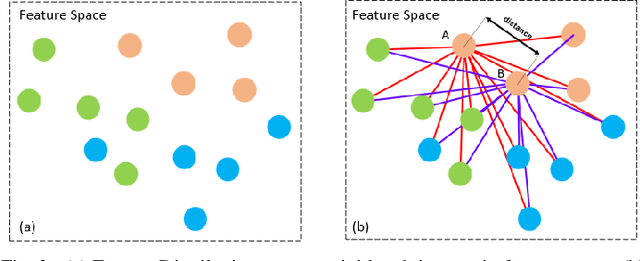
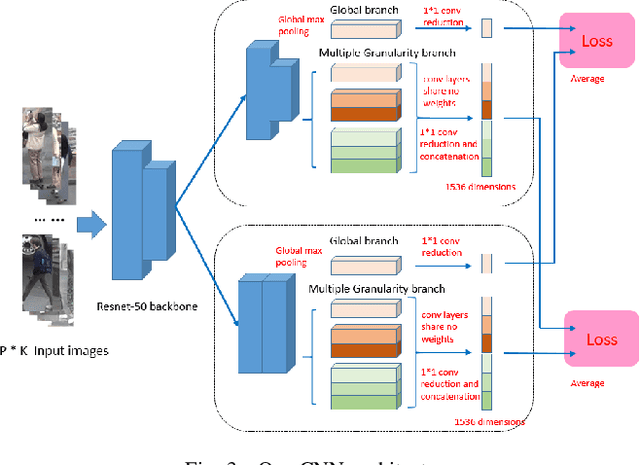

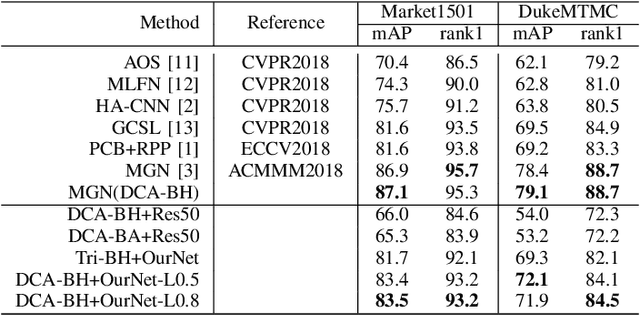
To learn the optimal similarity function between probe and gallery images in Person re-identification, effective deep metric learning methods have been extensively explored to obtain discriminative feature embedding. However, existing metric loss like triplet loss and its variants always emphasize pair-wise relations but ignore the distribution context in feature space, leading to inconsistency and sub-optimal. In fact, the similarity of one pair not only decides the match of this pair, but also has potential impacts on other sample pairs. In this paper, we propose a novel Distribution Context Aware (DCA) loss based on triplet loss to combine both numerical similarity and relation similarity in feature space for better clustering. Extensive experiments on three benchmarks including Market-1501, DukeMTMC-reID and MSMT17, evidence the favorable performance of our method against the corresponding baseline and other state-of-the-art methods.