 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement Challenge: From Regularization to Reconstruction
Paper and Code
Nov 30, 2019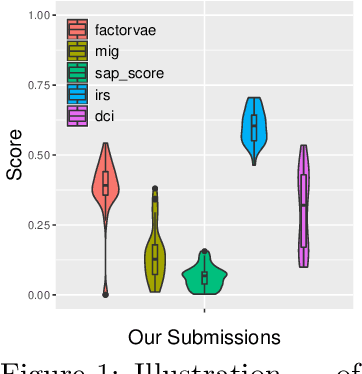

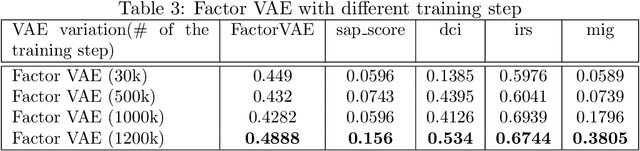

The challenge of learning disentangled representation has recently attracted much attention and boils down to a competition using a new real world disentanglement dataset (Gondal et al., 2019). Various methods based on variational auto-encoder have been proposed to solve this problem, by enforcing the independence between the representation and modifying the regularization term in the variational lower bound. However recent work by Locatello et al. (2018) has demonstrated that the proposed methods are heavily influenced by randomness and the choice of the hyper-parameter. In this work, instead of designing a new regularization term, we adopt the FactorVAE but improve the reconstruction performance and increase the capacity of network and the training step. The strategy turns out to be very effective and achieve the 1st place in the challenge.