 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction and Prioritized Exploration for Policy Search
Paper and Code
Mar 19, 2022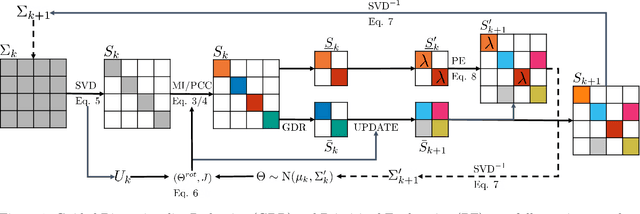


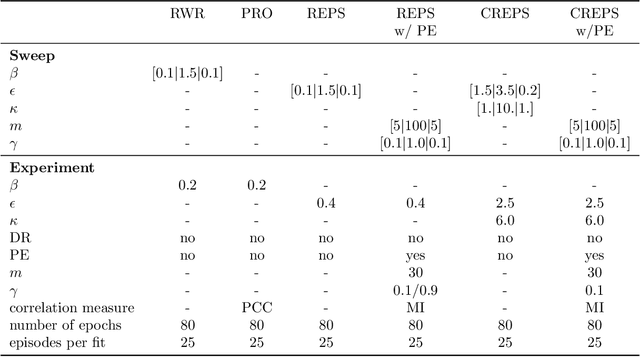
Black-box policy optimization is a class of reinforcement learning algorithms that explores and updates the policies at the parameter level. This class of algorithms is widely applied in robotics with movement primitives or non-differentiable policies. Furthermore, these approaches are particularly relevant where exploration at the action level could cause actuator damage or other safety issues. However, Black-box optimization does not scale well with the increasing dimensionality of the policy, leading to high demand for samples, which are expensive to obtain in real-world systems. In many practical applications, policy parameters do not contribute equally to the return. Identifying the most relevant parameters allows to narrow down the exploration and speed up the learning. Furthermore, updating only the effective parameters requires fewer samples, improving the scalability of the method. We present a novel method to prioritize the exploration of effective parameters and cope with full covariance matrix updates. Our algorithm learns faster than recent approaches and requires fewer samples to achieve state-of-the-art results. To select the effective parameters, we consider both the Pearson correlation coefficient and the Mutual Information. We showcase the capabilities of our approach on the Relative Entropy Policy Search algorithm in several simulated environments, including robotics simulations. Code is available at https://git.ias.informatik.tu-darmstadt.de/ias\_code/aistats2022/dr-creps}{git.ias.informatik.tu-darmstadt.de/ias\_code/aistats2022/dr-creps.