 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Scene Graphs
Paper and Code
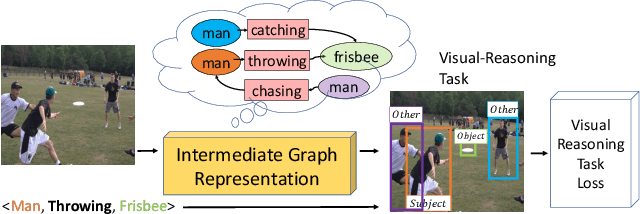
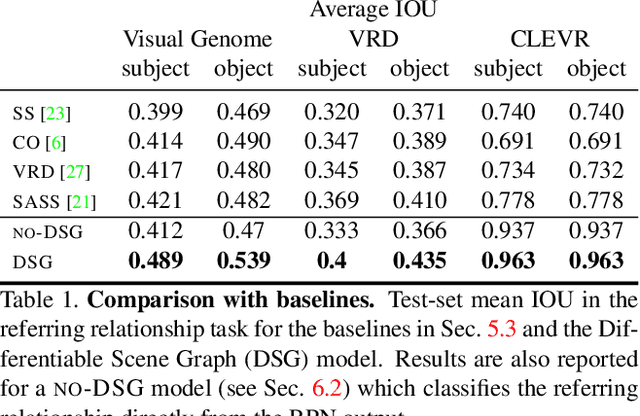
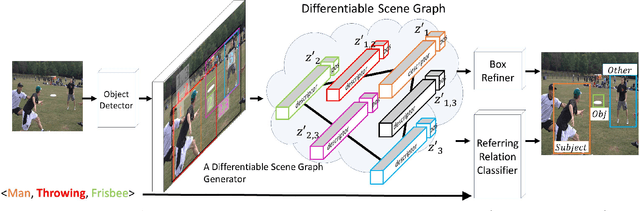
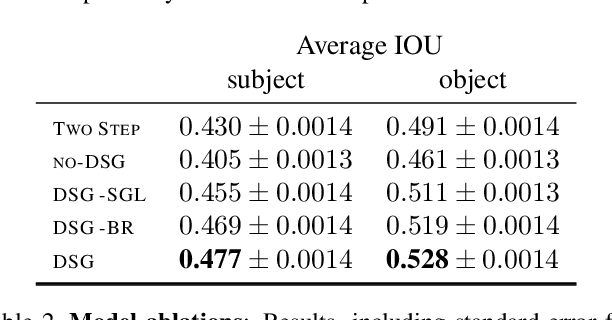
Understanding the semantics of complex visual scenes involves perception of entities and reasoning about their relations. Scene graphs provide a natural representation for these tasks, by assigning labels to both entities (nodes) and relations (edges). However, scene graphs are not commonly used as intermediate components in visual reasoning systems, for two complementary reasons. First, training models to map images to scene graphs requires prohibitive manual annotation, and results in graphs that often do not match the needs of a downstream visual reasoning application. Second, using these discrete graphs as an intermediate latent representation results in a non-differentiable function that is difficult to optimize. Here we propose Differentiable Scene Graphs (DSGs), an image representation that is amenable to differentiable end-to-end optimization, and requires supervision only from the downstream tasks. DSGs provide a dense representation for all regions and pairs of regions, investing model capacity on the important aspects of the image. We describe a multi-task objective function that allows us to learn this representation from indirect supervision only, provided by the downstream task. We evaluate our model on the challenging task of identifying referring relationships, and show that training DSGs using our multi-task objective leads to new state-of-the-art performance.