 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Far-Field Speaker System Via Teacher-Student Learning
Paper and Code
Apr 14, 2018
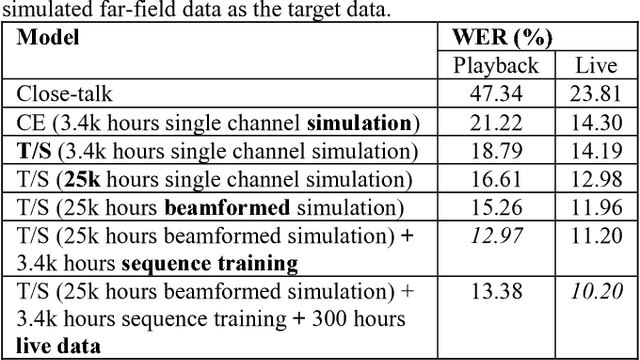
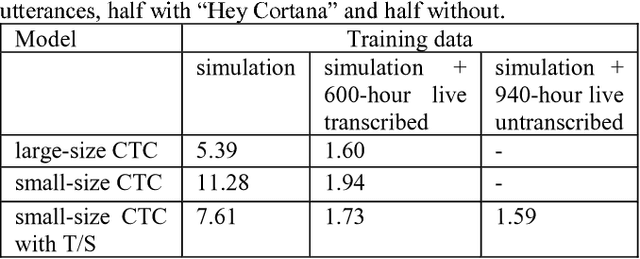
In this study, we develop the keyword spotting (KWS) and acoustic model (AM) components in a far-field speaker system. Specifically, we use teacher-student (T/S) learning to adapt a close-talk well-trained production AM to far-field by using parallel close-talk and simulated far-field data. We also use T/S learning to compress a large-size KWS model into a small-size one to fit the device computational cost. Without the need of transcription, T/S learning well utilizes untranscribed data to boost the model performance in both the AM adaptation and KWS model compression. We further optimize the models with sequence discriminative training and live data to reach the best performance of systems. The adapted AM improved from the baseline by 72.60% and 57.16% relative word error rate reduction on play-back and live test data, respectively. The final KWS model size was reduced by 27 times from a large-size KWS model without losing accuracy.