 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Trojaned DNNs Using Counterfactual Attributions
Paper and Code
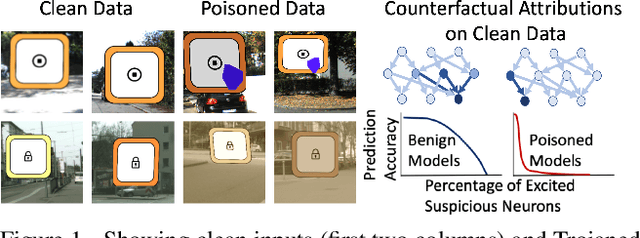
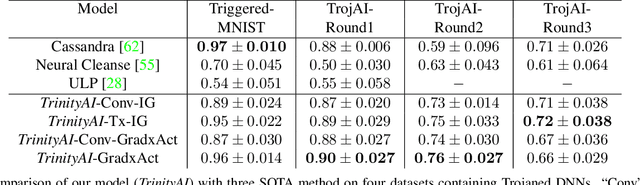
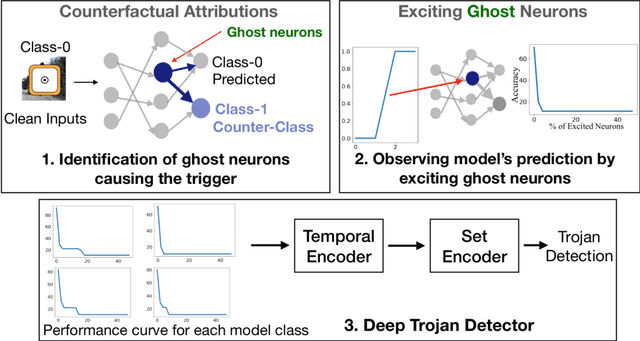
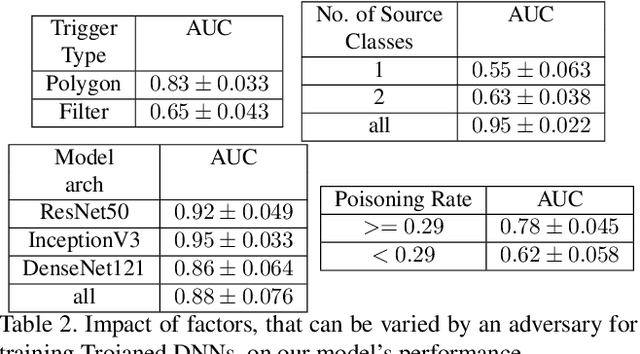
We target the problem of detecting Trojans or backdoors in DNNs. Such models behave normally with typical inputs but produce specific incorrect predictions for inputs poisoned with a Trojan trigger. Our approach is based on a novel observation that the trigger behavior depends on a few ghost neurons that activate on trigger pattern and exhibit abnormally higher relative attribution for wrong decisions when activated. Further, these trigger neurons are also active on normal inputs of the target class. Thus, we use counterfactual attributions to localize these ghost neurons from clean inputs and then incrementally excite them to observe changes in the model's accuracy. We use this information for Trojan detection by using a deep set encoder that enables invariance to the number of model classes, architecture, etc. Our approach is implemented in the TrinityAI tool that exploits the synergies between trustworthiness, resilience, and interpretability challenges in deep learning. We evaluate our approach on benchmarks with high diversity in model architectures, triggers, etc. We show consistent gains (+10%) over state-of-the-art methods that rely on the susceptibility of the DNN to specific adversarial attacks, which in turn requires strong assumptions on the nature of the Trojan attack.