Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Free & Order-Robust Optimisation
Paper and Code
Oct 22, 2019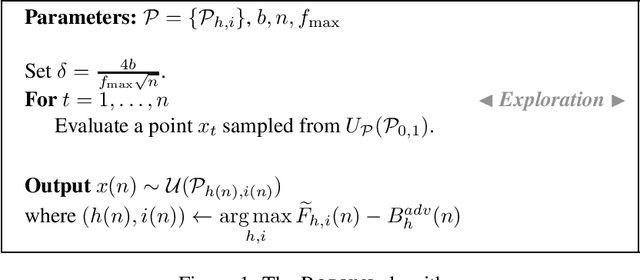
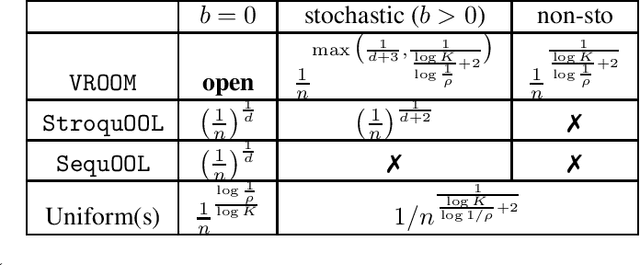

In this paper, we formalise order-robust optimisation as an instance of online learning minimising simple regret, and propose Vroom, a zero'th order optimisation algorithm capable of achieving vanishing regret in non-stationary environments, while recovering favorable rates under stochastic reward-generating processes. Our results are the first to target simple regret definitions in adversarial scenarios unveiling a challenge that has been rarely considered in prior work.
View paper on