 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Coefficients for Depth Completion
Paper and Code
Mar 13, 2019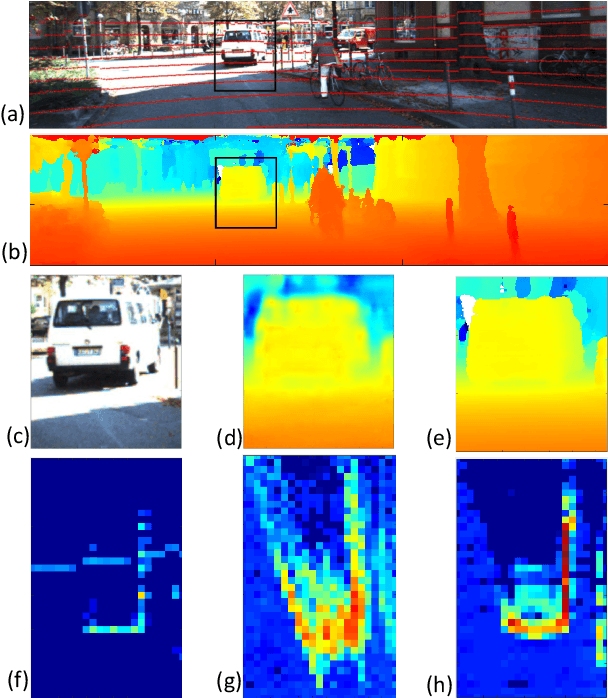

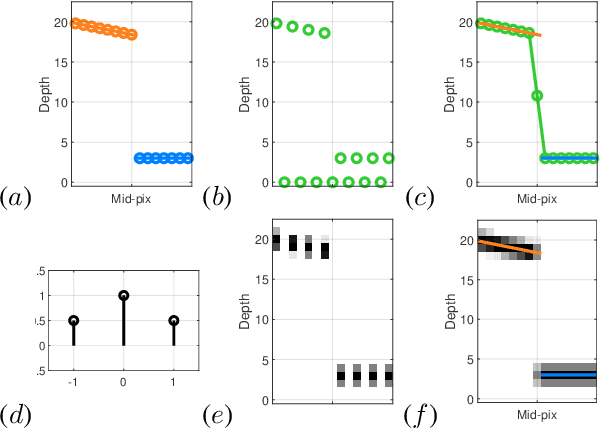
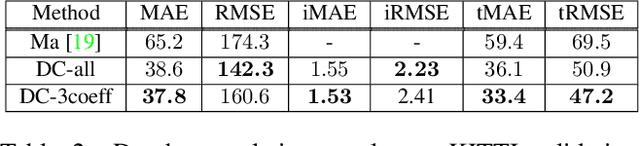
Depth completion involves estimating a dense depth image from sparse depth measurements, often guided by a color image. While linear upsampling is straight forward, it results in artifacts including depth pixels being interpolated in empty space across discontinuities between objects. Current methods use deep networks to upsample and "complete" the missing depth pixels. Nevertheless, depth smearing between objects remains a challenge. We propose a new representation for depth called Depth Coefficients (DC) to address this problem. It enables convolutions to more easily avoid inter-object depth mixing. We also show that the standard Mean Squared Error (MSE) loss function can promote depth mixing, and thus propose instead to use cross-entropy loss for DC. With quantitative and qualitative evaluation on benchmarks, we show that switching out sparse depth input and MSE loss with our DC representation and cross-entropy loss is a simple way to improve depth completion performance, and reduce pixel depth mixing, which leads to improved depth-based object detection.