 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Captioning with Joint Inference and Visual Context
Paper and Code
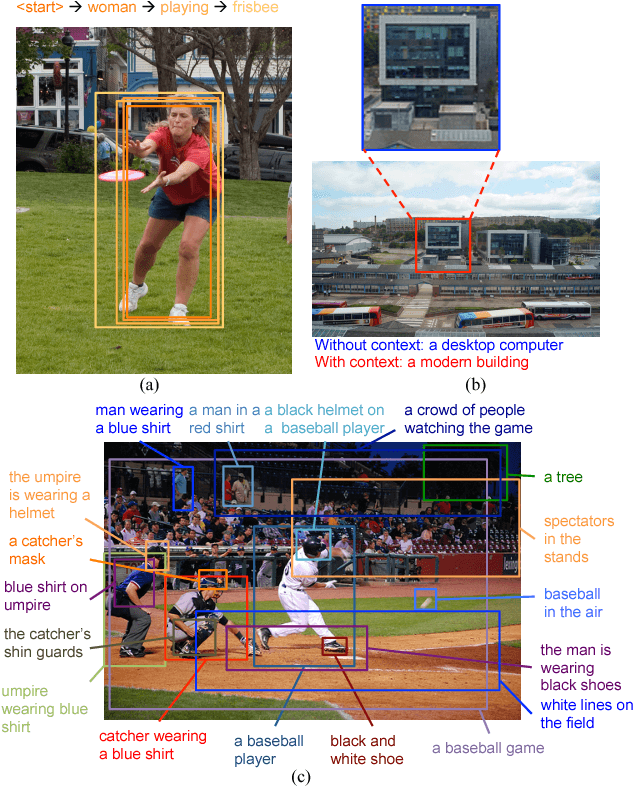



Dense captioning is a newly emerging computer vision topic for understanding images with dense language descriptions. The goal is to densely detect visual concepts (e.g., objects, object parts, and interactions between them) from images, labeling each with a short descriptive phrase. We identify two key challenges of dense captioning that need to be properly addressed when tackling the problem. First, dense visual concept annotations in each image are associated with highly overlapping target regions, making accurate localization of each visual concept challenging. Second, the large amount of visual concepts makes it hard to recognize each of them by appearance alone. We propose a new model pipeline based on two novel ideas, joint inference and context fusion, to alleviate these two challenges. We design our model architecture in a methodical manner and thoroughly evaluate the variations in architecture. Our final model, compact and efficient, achieves state-of-the-art accuracy on Visual Genome for dense captioning with a relative gain of 73\% compared to the previous best algorithm. Qualitative experiments also reveal the semantic capabilities of our model in dense captioning.