 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Prompts in Language Models via Perplexity Estimation
Paper and Code
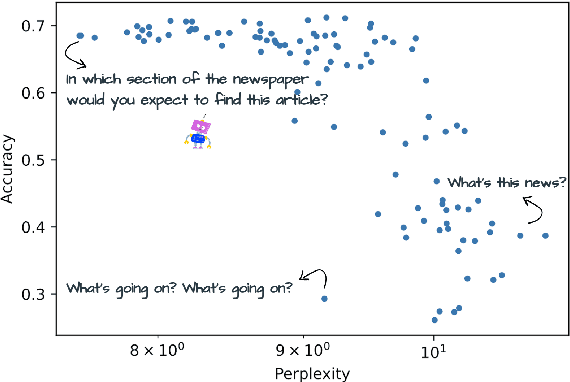


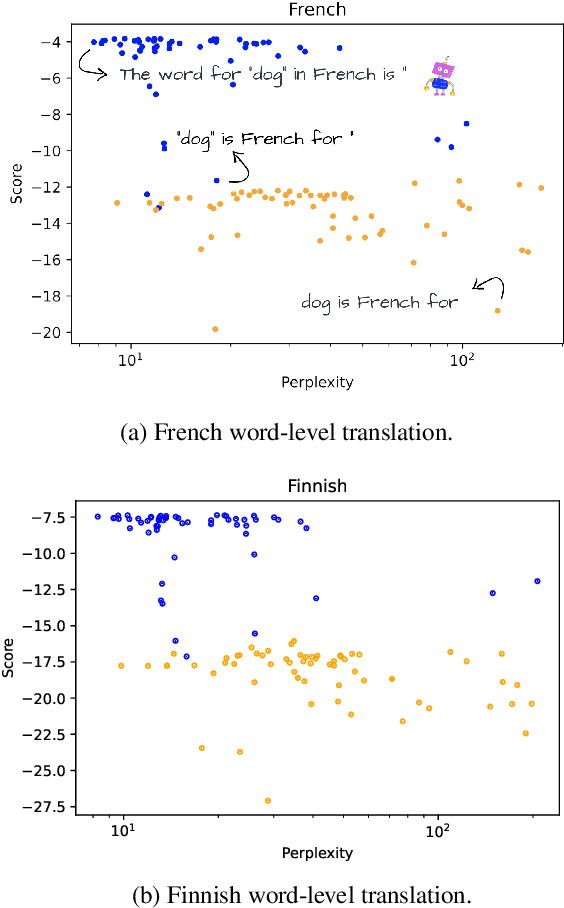
Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.