 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving Globally into Texture and Structure for Image Inpainting
Paper and Code


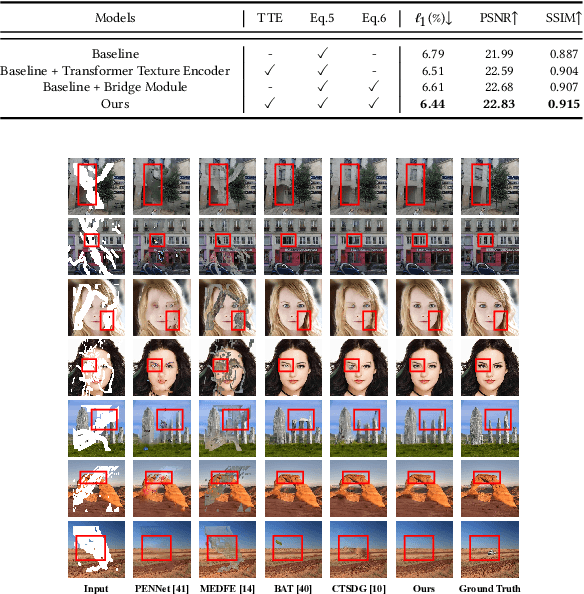

Image inpainting has achieved remarkable progress and inspired abundant methods, where the critical bottleneck is identified as how to fulfill the high-frequency structure and low-frequency texture information on the masked regions with semantics. To this end, deep models exhibit powerful superiority to capture them, yet constrained on the local spatial regions. In this paper, we delve globally into texture and structure information to well capture the semantics for image inpainting. As opposed to the existing arts trapped on the independent local patches, the texture information of each patch is reconstructed from all other patches across the whole image, to match the coarsely filled information, specially the structure information over the masked regions. Unlike the current decoder-only transformer within the pixel level for image inpainting, our model adopts the transformer pipeline paired with both encoder and decoder. On one hand, the encoder captures the texture semantic correlations of all patches across image via self-attention module. On the other hand, an adaptive patch vocabulary is dynamically established in the decoder for the filled patches over the masked regions. Building on this, a structure-texture matching attention module anchored on the known regions comes up to marry the best of these two worlds for progressive inpainting via a probabilistic diffusion process. Our model is orthogonal to the fashionable arts, such as Convolutional Neural Networks (CNNs), Attention and Transformer model, from the perspective of texture and structure information for image inpainting. The extensive experiments over the benchmarks validate its superiority. Our code is available at https://github.com/htyjers/DGTS-Inpainting.