 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaSpace: A Semantic-aligned Feature Space for Flexible Text-guided Image Editing
Paper and Code
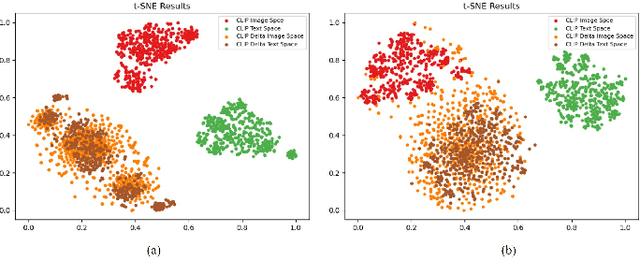



Text-guided image editing faces significant challenges to training and inference flexibility. Much literature collects large amounts of annotated image-text pairs to train text-conditioned generative models from scratch, which is expensive and not efficient. After that, some approaches that leverage pre-trained vision-language models are put forward to avoid data collection, but they are also limited by either per text-prompt optimization or inference-time hyper-parameters tuning. To address these issues, we investigate and identify a specific space, referred to as CLIP DeltaSpace, where the CLIP visual feature difference of two images is semantically aligned with the CLIP textual feature difference of their corresponding text descriptions. Based on DeltaSpace, we propose a novel framework called DeltaEdit, which maps the CLIP visual feature differences to the latent space directions of a generative model during the training phase, and predicts the latent space directions from the CLIP textual feature differences during the inference phase. And this design endows DeltaEdit with two advantages: (1) text-free training; (2) generalization to various text prompts for zero-shot inference. Extensive experiments validate the effectiveness and versatility of DeltaEdit with different generative models, including both the GAN model and the diffusion model, in achieving flexible text-guided image editing. Code is available at https://github.com/Yueming6568/DeltaEdit.