 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Cross-Attention Transformer for Medical Image Registration
Paper and Code
Mar 10, 2023


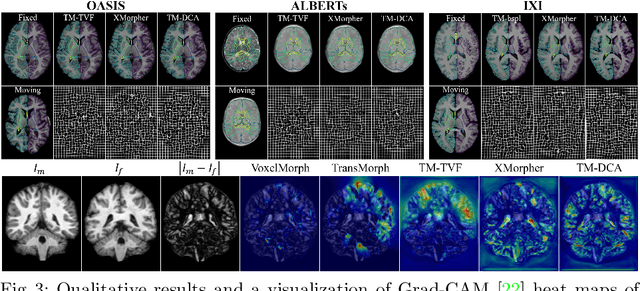
Transformers have recently shown promise for medical image applications, leading to an increasing interest in developing such models for medical image registration. Recent advancements in designing registration Transformers have focused on using cross-attention (CA) to enable a more precise understanding of spatial correspondences between moving and fixed images. Here, we propose a novel CA mechanism that computes windowed attention using deformable windows. In contrast to existing CA mechanisms that require intensive computational complexity by either computing CA globally or locally with a fixed and expanded search window, the proposed deformable CA can selectively sample a diverse set of features over a large search window while maintaining low computational complexity. The proposed model was extensively evaluated on multi-modal, mono-modal, and atlas-to-patient registration tasks, demonstrating promising performance against state-of-the-art methods and indicating its effectiveness for medical image registration. The source code for this work will be available after publication.