 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Structured Scene Parsing by Learning with Image Descriptions
Paper and Code
Feb 28, 2018


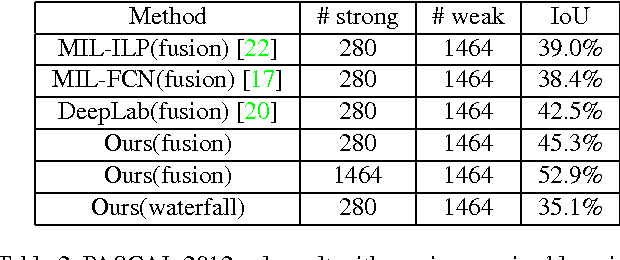
This paper addresses a fundamental problem of scene understanding: How to parse the scene image into a structured configuration (i.e., a semantic object hierarchy with object interaction relations) that finely accords with human perception. We propose a deep architecture consisting of two networks: i) a convolutional neural network (CNN) extracting the image representation for pixelwise object labeling and ii) a recursive neural network (RNN) discovering the hierarchical object structure and the inter-object relations. Rather than relying on elaborative user annotations (e.g., manually labeling semantic maps and relations), we train our deep model in a weakly-supervised manner by leveraging the descriptive sentences of the training images. Specifically, we decompose each sentence into a semantic tree consisting of nouns and verb phrases, and facilitate these trees discovering the configurations of the training images. Once these scene configurations are determined, then the parameters of both the CNN and RNN are updated accordingly by back propagation. The entire model training is accomplished through an Expectation-Maximization method. Extensive experiments suggest that our model is capable of producing meaningful and structured scene configurations and achieving more favorable scene labeling performance on PASCAL VOC 2012 over other state-of-the-art weakly-supervised methods.