 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Clustering with Category-Style Representation
Paper and Code
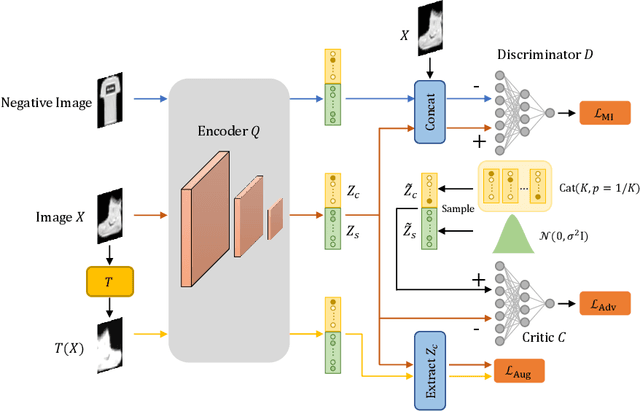
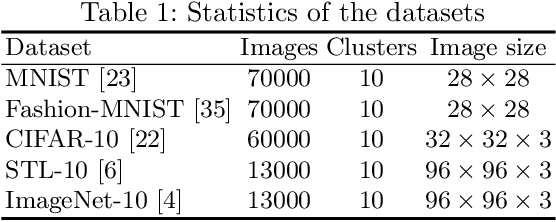

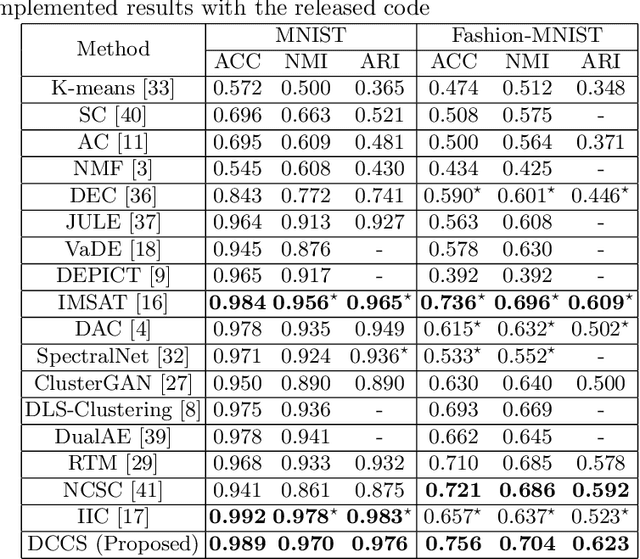
Deep clustering which adopts deep neural networks to obtain optimal representations for clustering has been widely studied recently. In this paper, we propose a novel deep image clustering framework to learn a category-style latent representation in which the category information is disentangled from image style and can be directly used as the cluster assignment. To achieve this goal, mutual information maximization is applied to embed relevant information in the latent representation. Moreover, augmentation-invariant loss is employed to disentangle the representation into category part and style part. Last but not least, a prior distribution is imposed on the latent representation to ensure the elements of the category vector can be used as the probabilities over clusters. Comprehensive experiments demonstrate that the proposed approach outperforms state-of-the-art methods significantly on five public datasets.