 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hierarchy in Bandits
Paper and Code
Feb 03, 2022
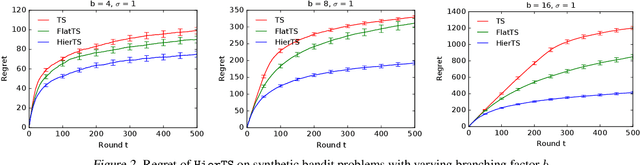

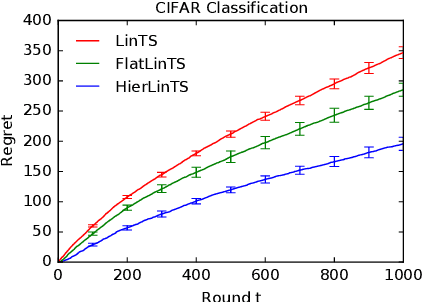
Mean rewards of actions are often correlated. The form of these correlations may be complex and unknown a priori, such as the preferences of a user for recommended products and their categories. To maximize statistical efficiency, it is important to leverage these correlations when learning. We formulate a bandit variant of this problem where the correlations of mean action rewards are represented by a hierarchical Bayesian model with latent variables. Since the hierarchy can have multiple layers, we call it deep. We propose a hierarchical Thompson sampling algorithm (HierTS) for this problem, and show how to implement it efficiently for Gaussian hierarchies. The efficient implementation is possible due to a novel exact hierarchical representation of the posterior, which itself is of independent interest. We use this exact posterior to analyze the Bayes regret of HierTS in Gaussian bandits. Our analysis reflects the structure of the problem, that the regret decreases with the prior width, and also shows that hierarchies reduce the regret by non-constant factors in the number of actions. We confirm these theoretical findings empirically, in both synthetic and real-world experiments.