 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep End2End Voxel2Voxel Prediction
Paper and Code
Nov 20, 2015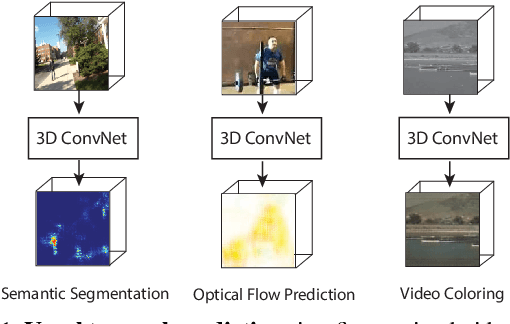

Over the last few years deep learning methods have emerged as one of the most prominent approaches for video analysis. However, so far their most successful applications have been in the area of video classification and detection, i.e., problems involving the prediction of a single class label or a handful of output variables per video. Furthermore, while deep networks are commonly recognized as the best models to use in these domains, there is a widespread perception that in order to yield successful results they often require time-consuming architecture search, manual tweaking of parameters and computationally intensive pre-processing or post-processing methods. In this paper we challenge these views by presenting a deep 3D convolutional architecture trained end to end to perform voxel-level prediction, i.e., to output a variable at every voxel of the video. Most importantly, we show that the same exact architecture can be used to achieve competitive results on three widely different voxel-prediction tasks: video semantic segmentation, optical flow estimation, and video coloring. The three networks learned on these problems are trained from raw video without any form of preprocessing and their outputs do not require post-processing to achieve outstanding performance. Thus, they offer an efficient alternative to traditional and much more computationally expensive methods in these video domains.