 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Contextual Recurrent Residual Networks for Scene Labeling
Paper and Code
Apr 12, 2017
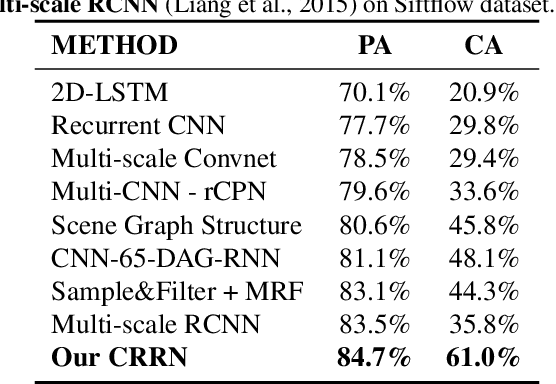
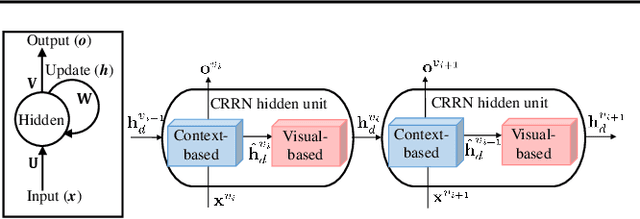

Designed as extremely deep architectures, deep residual networks which provide a rich visual representation and offer robust convergence behaviors have recently achieved exceptional performance in numerous computer vision problems. Being directly applied to a scene labeling problem, however, they were limited to capture long-range contextual dependence, which is a critical aspect. To address this issue, we propose a novel approach, Contextual Recurrent Residual Networks (CRRN) which is able to simultaneously handle rich visual representation learning and long-range context modeling within a fully end-to-end deep network. Furthermore, our proposed end-to-end CRRN is completely trained from scratch, without using any pre-trained models in contrast to most existing methods usually fine-tuned from the state-of-the-art pre-trained models, e.g. VGG-16, ResNet, etc. The experiments are conducted on four challenging scene labeling datasets, i.e. SiftFlow, CamVid, Stanford background and SUN datasets, and compared against various state-of-the-art scene labeling methods.