 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCoOp: Robust Prompt Tuning with Out-of-Distribution Detection
Paper and Code
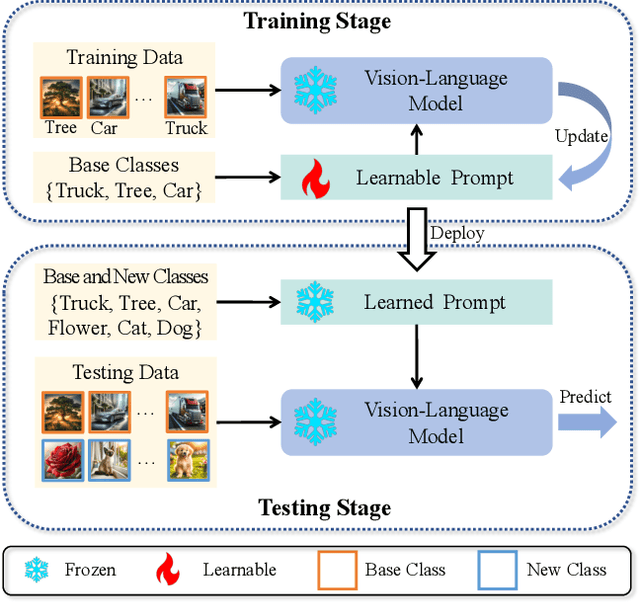

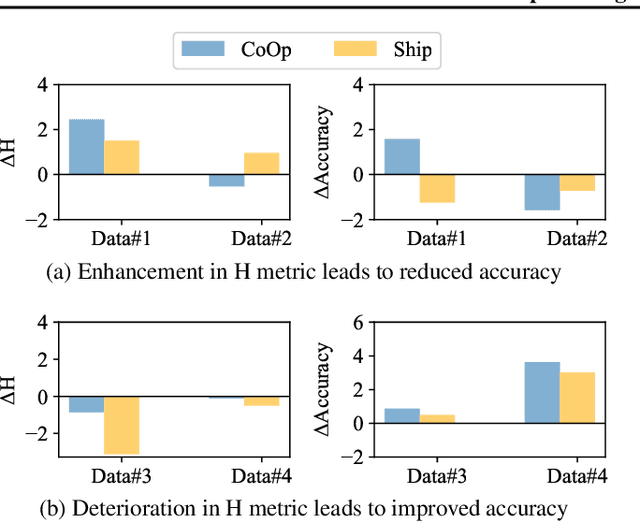
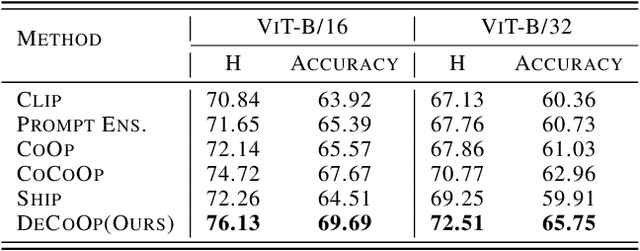
Vision-language models (VLMs), such as CLIP, have demonstrated impressive zero-shot capabilities for various downstream tasks. Their performance can be further enhanced through few-shot prompt tuning methods. However, current studies evaluate the performance of learned prompts separately on base and new classes. This evaluation lacks practicality for real-world applications since downstream tasks cannot determine whether the data belongs to base or new classes in advance. In this paper, we explore a problem setting called Open-world Prompt Tuning (OPT), which involves tuning prompts on base classes and evaluating on a combination of base and new classes. By introducing Decomposed Prompt Tuning framework (DePT), we theoretically demonstrate that OPT can be solved by incorporating out-of-distribution detection into prompt tuning, thereby enhancing the base-to-new discriminability. Based on DePT, we present a novel prompt tuning approach, namely, Decomposed Context Optimization (DeCoOp), which introduces new-class detectors and sub-classifiers to further enhance the base-class and new-class discriminability. Experimental results on 11 benchmark datasets validate the effectiveness of DePT and demonstrate that DeCoOp outperforms current state-of-the-art methods, providing a significant 2% average accuracy improvement.