 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Mamba: A Multi-Grained State Space Model with Self-Evolution Regularization for Offline RL
Paper and Code

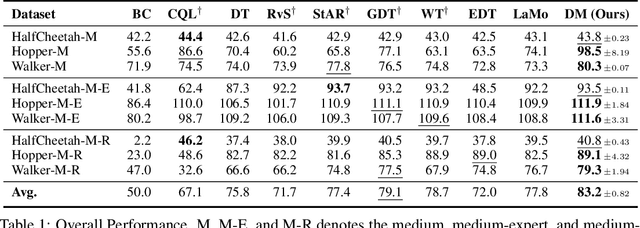
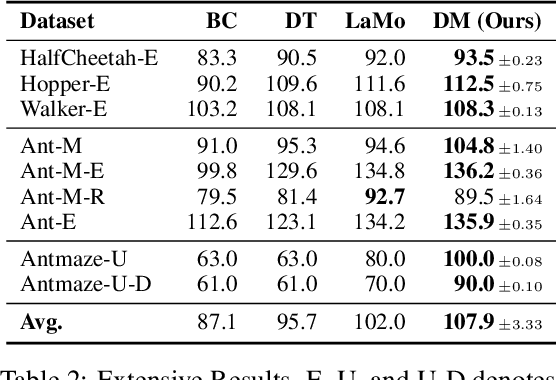

While the conditional sequence modeling with the transformer architecture has demonstrated its effectiveness in dealing with offline reinforcement learning (RL) tasks, it is struggle to handle out-of-distribution states and actions. Existing work attempts to address this issue by data augmentation with the learned policy or adding extra constraints with the value-based RL algorithm. However, these studies still fail to overcome the following challenges: (1) insufficiently utilizing the historical temporal information among inter-steps, (2) overlooking the local intrastep relationships among states, actions and return-to-gos (RTGs), (3) overfitting suboptimal trajectories with noisy labels. To address these challenges, we propose Decision Mamba (DM), a novel multi-grained state space model (SSM) with a self-evolving policy learning strategy. DM explicitly models the historical hidden state to extract the temporal information by using the mamba architecture. To capture the relationship among state-action-RTG triplets, a fine-grained SSM module is designed and integrated into the original coarse-grained SSM in mamba, resulting in a novel mamba architecture tailored for offline RL. Finally, to mitigate the overfitting issue on noisy trajectories, a self-evolving policy is proposed by using progressive regularization. The policy evolves by using its own past knowledge to refine the suboptimal actions, thus enhancing its robustness on noisy demonstrations. Extensive experiments on various tasks show that DM outperforms other baselines substantially.