 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-identifying Hospital Discharge Summaries: An End-to-End Framework using Ensemble of De-Identifiers
Paper and Code
Jan 01, 2021
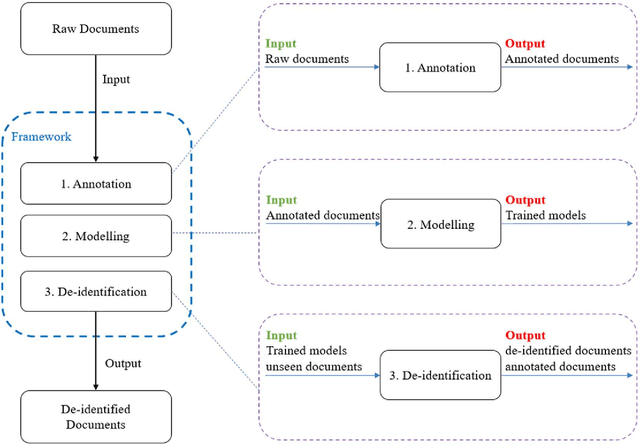
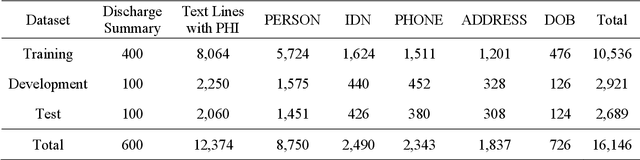
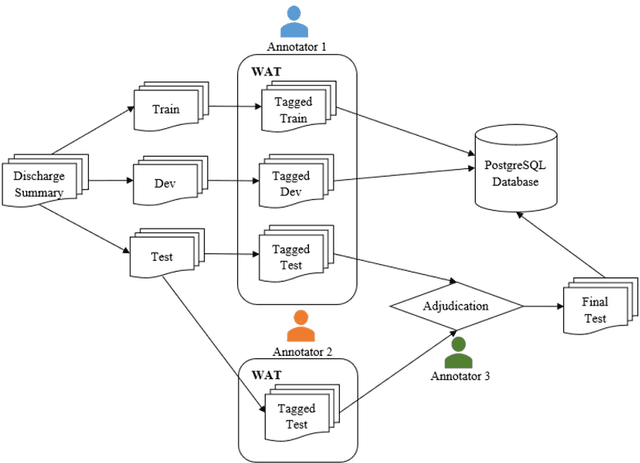
Objective:Electronic Medical Records (EMRs) contain clinical narrative text that is of great potential value to medical researchers. However, this information is mixed with Protected Health Information (PHI) that presents risks to patient and clinician confidentiality. This paper presents an end-to-end de-identification framework to automatically remove PHI from hospital discharge summaries. Materials and Methods:Our corpus included 600 hospital discharge summaries which were extracted from the EMRs of two principal referral hospitals in Sydney, Australia. Our end-to-end de-identification framework consists of three components: 1) Annotation: labelling of PHI in the 600 hospital discharge summaries using five pre-defined categories: person, address, date of birth, individual identification number, phone/fax number; 2) Modelling: training and evaluating ensembles of named entity recognition (NER) models through the use of three natural language processing (NLP) toolkits (Stanza, FLAIR and spaCy) and both balanced and imbalanced datasets; and 3) De-identification: removing PHI from the hospital discharge summaries. Results:The final model in our framework was an ensemble which combined six single models using both balanced and imbalanced datasets for training majority voting. It achieved 0.9866 precision, 0.9862 recall and 0.9864 F1 scores. The majority of false positives and false negatives were related to the person category. Discussion:Our study showed that the ensemble of different models which were trained using three different NLP toolkits upon balanced and imbalanced datasets can achieve good results even with a relatively small corpus. Conclusion:Our end-to-end framework provides a robust solution to de-identifying clinical narrative corpuses safely. It can be easily applied to any kind of clinical narrative documents.