 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-coupling and De-positioning Dense Self-supervised Learning
Paper and Code
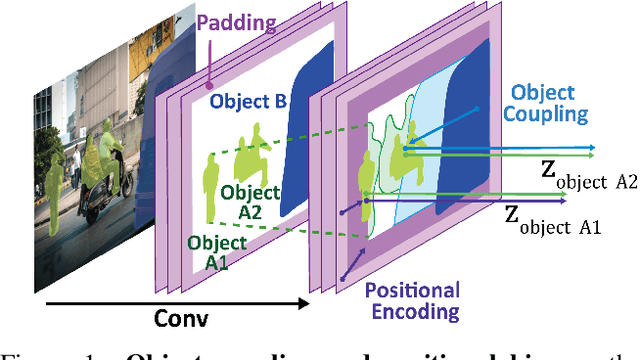
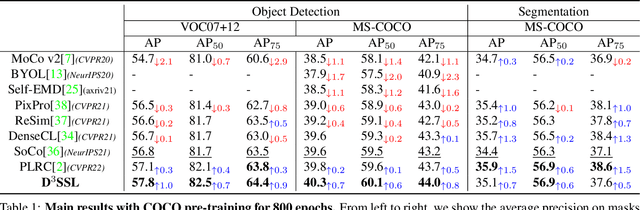
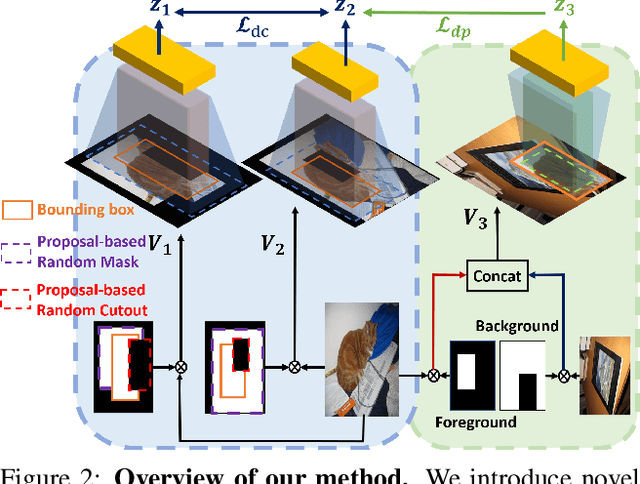

Dense Self-Supervised Learning (SSL) methods address the limitations of using image-level feature representations when handling images with multiple objects. Although the dense features extracted by employing segmentation maps and bounding boxes allow networks to perform SSL for each object, we show that they suffer from coupling and positional bias, which arise from the receptive field increasing with layer depth and zero-padding. We address this by introducing three data augmentation strategies, and leveraging them in (i) a decoupling module that aims to robustify the network to variations in the object's surroundings, and (ii) a de-positioning module that encourages the network to discard positional object information. We demonstrate the benefits of our method on COCO and on a new challenging benchmark, OpenImage-MINI, for object classification, semantic segmentation, and object detection. Our extensive experiments evidence the better generalization of our method compared to the SOTA dense SSL methods