 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBS: Dynamic Batch Size For Distributed Deep Neural Network Training
Paper and Code
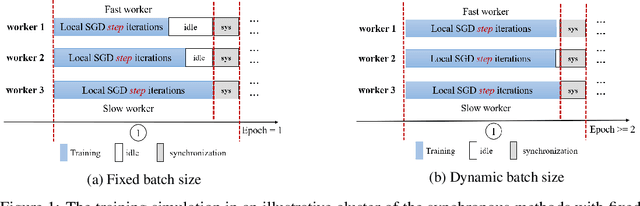
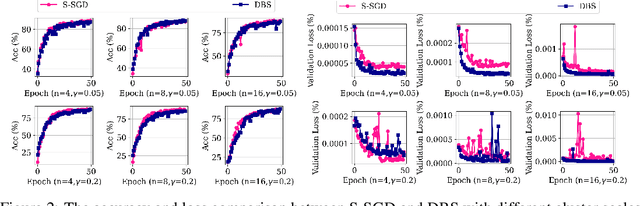
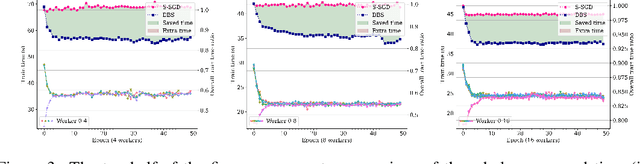
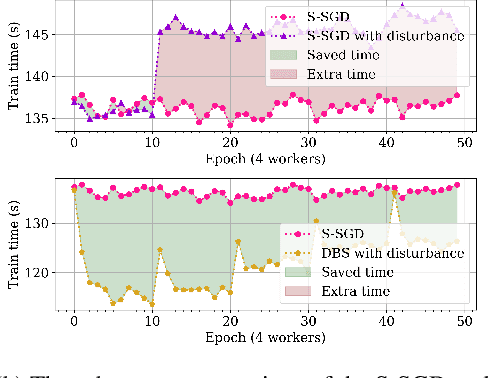
Synchronous strategies with data parallelism, such as the Synchronous StochasticGradient Descent (S-SGD) and the model averaging methods, are widely utilizedin distributed training of Deep Neural Networks (DNNs), largely owing to itseasy implementation yet promising performance. Particularly, each worker ofthe cluster hosts a copy of the DNN and an evenly divided share of the datasetwith the fixed mini-batch size, to keep the training of DNNs convergence. In thestrategies, the workers with different computational capability, need to wait foreach other because of the synchronization and delays in network transmission,which will inevitably result in the high-performance workers wasting computation.Consequently, the utilization of the cluster is relatively low. To alleviate thisissue, we propose the Dynamic Batch Size (DBS) strategy for the distributedtraining of DNNs. Specifically, the performance of each worker is evaluatedfirst based on the fact in the previous epoch, and then the batch size and datasetpartition are dynamically adjusted in consideration of the current performanceof the worker, thereby improving the utilization of the cluster. To verify theeffectiveness of the proposed strategy, extensive experiments have been conducted,and the experimental results indicate that the proposed strategy can fully utilizethe performance of the cluster, reduce the training time, and have good robustnesswith disturbance by irrelevant tasks. Furthermore, rigorous theoretical analysis hasalso been provided to prove the convergence of the proposed strategy.