 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling
Paper and Code
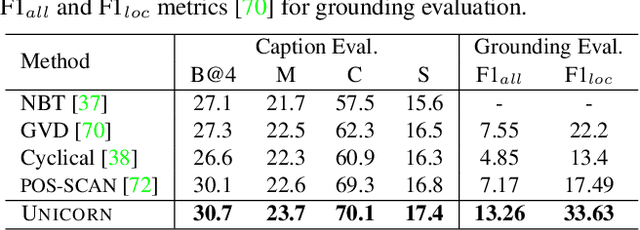
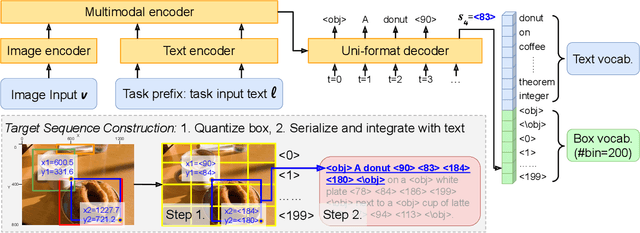
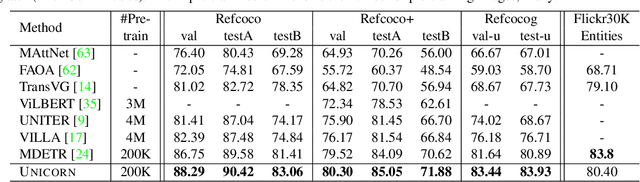
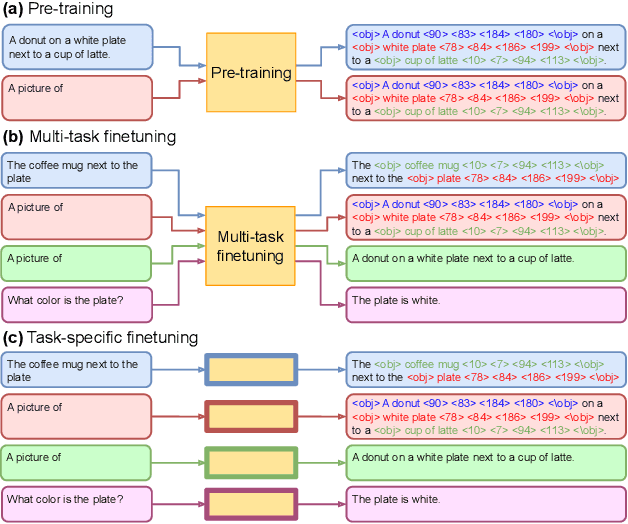
In this paper, we propose UNICORN, a vision-language (VL) model that unifies text generation and bounding box prediction into a single architecture. Specifically, we quantize each box into four discrete box tokens and serialize them as a sequence, which can be integrated with text tokens. We formulate all VL problems as a generation task, where the target sequence consists of the integrated text and box tokens. We then train a transformer encoder-decoder to predict the target in an auto-regressive manner. With such a unified framework and input-output format, UNICORN achieves comparable performance to task-specific state of the art on 7 VL benchmarks, covering the visual grounding, grounded captioning, visual question answering, and image captioning tasks. When trained with multi-task finetuning, UNICORN can approach different VL tasks with a single set of parameters, thus crossing downstream task boundary. We show that having a single model not only saves parameters, but also further boosts the model performance on certain tasks. Finally, UNICORN shows the capability of generalizing to new tasks such as ImageNet object localization.