 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer via Semantic Skill Imitation
Paper and Code


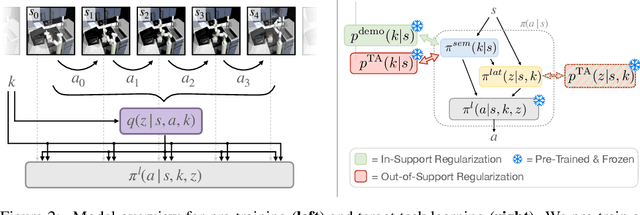

We propose an approach for semantic imitation, which uses demonstrations from a source domain, e.g. human videos, to accelerate reinforcement learning (RL) in a different target domain, e.g. a robotic manipulator in a simulated kitchen. Instead of imitating low-level actions like joint velocities, our approach imitates the sequence of demonstrated semantic skills like "opening the microwave" or "turning on the stove". This allows us to transfer demonstrations across environments (e.g. real-world to simulated kitchen) and agent embodiments (e.g. bimanual human demonstration to robotic arm). We evaluate on three challenging cross-domain learning problems and match the performance of demonstration-accelerated RL approaches that require in-domain demonstrations. In a simulated kitchen environment, our approach learns long-horizon robot manipulation tasks, using less than 3 minutes of human video demonstrations from a real-world kitchen. This enables scaling robot learning via the reuse of demonstrations, e.g. collected as human videos, for learning in any number of target domains.