 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCowClip: Reducing CTR Prediction Model Training Time from 12 hours to 10 minutes on 1 GPU
Paper and Code
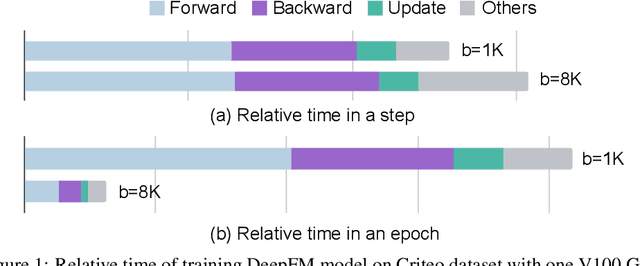
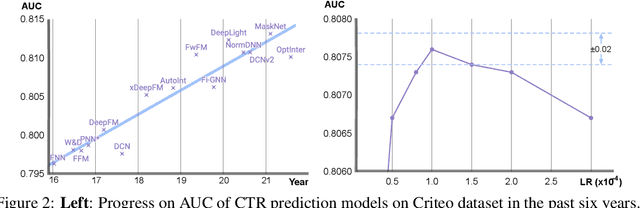
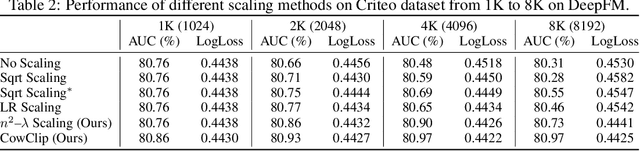
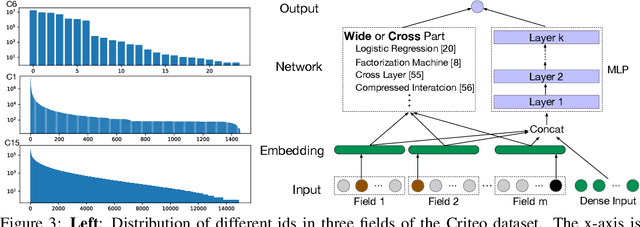
The click-through rate (CTR) prediction task is to predict whether a user will click on the recommended item. As mind-boggling amounts of data are produced online daily, accelerating CTR prediction model training is critical to ensuring an up-to-date model and reducing the training cost. One approach to increase the training speed is to apply large batch training. However, as shown in computer vision and natural language processing tasks, training with a large batch easily suffers from the loss of accuracy. Our experiments show that previous scaling rules fail in the training of CTR prediction neural networks. To tackle this problem, we first theoretically show that different frequencies of ids make it challenging to scale hyperparameters when scaling the batch size. To stabilize the training process in a large batch size setting, we develop the adaptive Column-wise Clipping (CowClip). It enables an easy and effective scaling rule for the embeddings, which keeps the learning rate unchanged and scales the L2 loss. We conduct extensive experiments with four CTR prediction networks on two real-world datasets and successfully scaled 128 times the original batch size without accuracy loss. In particular, for CTR prediction model DeepFM training on the Criteo dataset, our optimization framework enlarges the batch size from 1K to 128K with over 0.1% AUC improvement and reduces training time from 12 hours to 10 minutes on a single V100 GPU. Our code locates at https://github.com/bytedance/LargeBatchCTR.